Workshop - Python in OpenRefine
 Folie - Python mit OpenRefine verwenden
Folie - Python mit OpenRefine verwendenWir verwenden Python zusammen mit OpenRefine.
Jython in der OpenRefine Dokumentation.
Einsteiger Workshop 19 Daten mit OpenRefine clustern.
Blogbeitrag Named Entity Recognition mit OpenRefine und spaCy.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
Jython
Quasi überall, wo man in OpenRefine GREL-Expressions schreiben kann, kann man stattdessen auch auf Jython umstellen. Also beispielsweise für den Transformations-Dialog, Facets oder neu auch für eigene Clustering Methoden.
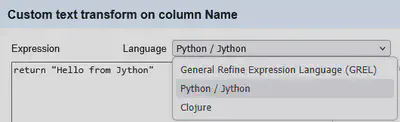
Praktisch wird das Jython-Snippet, welches man wie in Abbildung 1 gezeigt im Dialog eingibt, in eine Python-Funktion gepackt und dann von Jython ausgeführt.
Daher benötigt man im Unterschied zu GREL ein return Statement, um anzugeben, welcher Wert zurückgegeben wird.
def some_fun_name(value, cell, cells, row, rowIndex, value1, value2):
...
Das eingegebene Snippet wird quasi anstelle von ... eingesetzt.
Zu den in GREL zur Verfügung stehenden Variablen haben wir schon einiges geschrieben. Diese stehen mit Ausnahmen in Jython unter OpenRefine ebenfalls zur Verfügung.
Beispielsweise fehlt die Variable columnName mit dem aktuellen Spaltennamen.
Jython selbst ist eine Java Implementierung von Python. Das bedeutet, dass es innerhalb von Java interpretiert wird und man auch von Jython Code aus auf verfügbare Java Methoden zugreifen kann.
Leider hat das Projekt den Sprung auf Python 3 nicht geschafft und unterstützt daher nur die Funktionalität von Python 2.7. Das macht auch die Verwendung von externen Python Bibliotheken innerhalb von Jython deutlich komplexer.
Es gibt nur noch selten Python Bibliotheken, die Python 2.7 unterstützen. Und es können auch nur Python Bibliotheken verwendet werden, die komplett in Python geschrieben wurden. Einige gerade sehr beliebte Python Projekte verwenden aus Performance Gründen unter der Haube kompilierte Programmiersprachen wie C, Fortran oder Rust. Diese können unter Jython nicht direkt verwendet werden.
Praktisch ist die Ausführung von Jython Code in OpenRefine auch deutlich langsamer, als z.B. GREL oder Clojure Code. Das macht es eher schwierig komplexere Algorithmen z.B. für das Clustering direkt zu hinterlegen.
Alternativ kann von OpenRefine aus, via Jython auf externen Python Code zugegriffen werden, was im folgenden Teil vertieft wird.
Python
Standard Setup
Wir verfolgen die Idee von OpenRefine aus auf Python Code zuzugreifen, der nicht innerhalb von Jython ausgeführt wird. Dafür benötigen wir einen Blick in das Python Projekt Setup.
Für ein typisches Python Projekt benötigt man fünf Schritte, die durch verschiedene Tools in unterschiedlichem Ausmaß unterstützt werden.
Schritt 1: Python Interpreter
Zuerst benötigt man einen Python Interpreter, der es ermöglicht Python Code auf dem eigenen Rechner auszuführen. Zur Verwaltung verschiedener Python Versionen auf dem Rechner gibt es zum Beispiel das Projekt pyenv.
Schritt 2: Dependency Management
Üblicherweise werden verschiedene externe Bibliotheken benötigt. Diese stehen zum Beispiel im Python Package Index (PyPI) zur Verfügung und können mit pip verwaltet werden.
Alternativen zur Verwaltung der Abhängigkeiten sind Poetry, pip-tools und pipx.
Schritt 3: Compiler
Wie schon angesprochen beinhalten manche Python Projekte nicht nur Python Code, sondern auch Code in kompilierten Sprachen. Wenn für die von euch verwendete Kombination aus CPU und Betriebssystem (noch) kein kompiliertes Binärpaket für die Bibliothek zur Verfügung steht, dann muss das Paket ggf. auf eurem Rechner kompiliert werden. Dafür werden entsprechende Compiler und Entwicklungspakete auf dem Rechner benötigt.
Alternativ gibt es auf conda-forge eine Sammlung schon kompilierter Pakete.
Schritt 4: Virtuelle Umgebung
Erfahrungsgemäß bleibt es nicht bei einem Python Projekt auf dem eigenen Rechner. Um Konflikte zwischen den Python Versionen und/oder Abhängigkeiten zu vermeiden, ist es üblich für jedes Projekt eine eigene virtuelle Umgebung anzulegen.
Dafür gibt es das Werkzeug venv, welches früher ein separates Paket war, und seit Python 3.3 in den Standard übernommen wurde.
Schritt 5: Package und Release Management
Möchte man das Projekt anschließend für andere z.B. im Python Package Index zur Verfügung stellen, dann muss es davor noch in das passende Paketformat umgewandelt werden. Da das für die Benutzung mit OpenRefine nicht relevant ist, wird dieser Schritt hier nicht vertieft.
uv
Das oben beschriebene Setup klingt recht kompliziert und daher abschreckend gerade für kleinere Experimente. Spätestens seit 2025 setzt sich bei Python Entwicklern hier das Projekt uv durch, welches die Schritte 1, 2, 4 und 5 in einem Werkzeug vereint und das Python Setup dadurch deutlich vereinfacht.
Für die Installation von uv werden mehrere einfache und direkte Wege beschrieben.
uv hat (quasi) drei für uns relevante Modi:
- uvx zum Ausführen von Tools.
- uv run zum Ausführen von Skripten.
- uv zum Arbeiten mit Projekten
(mehrere abhängige Python Dateien, separates Dependency Management).
Wir konzentrieren uns in dieser Anleitung auf die ersten beiden.
Reconciliation Service
Um die Verwendung von uvx zum Ausführen von externen Python Werkzeugen zu demonstrieren, erstellen wir einen eigenen Reconciliation Service basierend auf einer CSV-Datei mit uvx und csv-reconcile. Zum Herunterladen der CSV-Datei von 12 Daten zwischen Projekten abgleichen verwenden wir uvx mit httpie.
In einem Terminal wie iTerm, xTerm, Bash oder Powershell führen wir den folgenden Befehl aus.
uvx --from httpie http --download GET https://fdmlab.landesarchiv-bw.de/data/openrefine-workshop/12_staedte-in-bw-geokoordinaten.csv
Dieses kompakte Snippet lädt die zu diesem Zeitpunkt standardmäßige Python Version und die aktuellste Version von httpie herunter, erstellt damit eine virtuelle Umgebung (venv) und führt darin den Befehl http --download GET ... aus.
Den Reconciliation Service basierend auf der im letzten Schritt heruntergeladenen Datei erstellen wir in zwei Schritten:
- Datenbank für Reconcilation Service erstellen
- Reconciliation Service starten
uvx csv-reconcile init 12_staedte-in-bw-geokoordinaten.csv "GND ID" "Name"
Mit diesem Snippet erstellen wir die Datenbank für den Reconciliation Service und legen die Spalte “GND ID” als ID-Spalte fest und die Spalte “Name” als Standardspalte für den Abgleich. Den Reconciliation Service selbst starten wir mit dem folgenden Befehl.
uvx csv-reconcile serve
In OpenRefine können wir den Reconciliation Service anschließend hinzufügen mit: http://127.0.0.1:5000/reconcile.
Datenbank mit eigener Konfiguration
Der oben erstelle Reconciliation Service ist recht generisch und es fehlt z.B. noch die Vorschaufunktion für die einzelnen Elemente.
Um den Service nach unseren Anforderungen zu konfigurieren, erstellen wir eine Datei config.py mit dem folgenden Inhalt.
SERVER_NAME="localhost:5000"
CSVKWARGS={'delimiter': ',', 'quotechar': '"'}
CSVENCODING='UTF-8'
MANIFEST = {
"name": "Städte in BW Reconciliation Service",
"identifierSpace": "https://normdaten.landesarchiv-bw.de/ids",
"schemaSpace": "https://normdaten.landesarchiv-bw.de/schema",
"extend": {
"propose_properties": {
"service_url": "http://localhost:5000",
"service_path": "/properties"
}
},
"preview": {
"url": "http://localhost:5000/preview/{{id}}",
"width": 500,
"height": 300
}
}
Anschließend erstellen wir die Reconciliation Datenbank mit der neuen Konfiguration.
uvx csv-reconcile init --config config.py 12_staedte-in-bw-geokoordinaten.csv "GND ID" "Name"
Der neue Service ist nach dem Starten unter http://localhost:5000/reconcile erreichbar.
uvx csv-reconcile serve
Der Reconciliation Service kann jetzt wie in Abbildung 2 mit dem Beispiel aus 12 Daten zwischen Projekten abgleichen getestet werden.
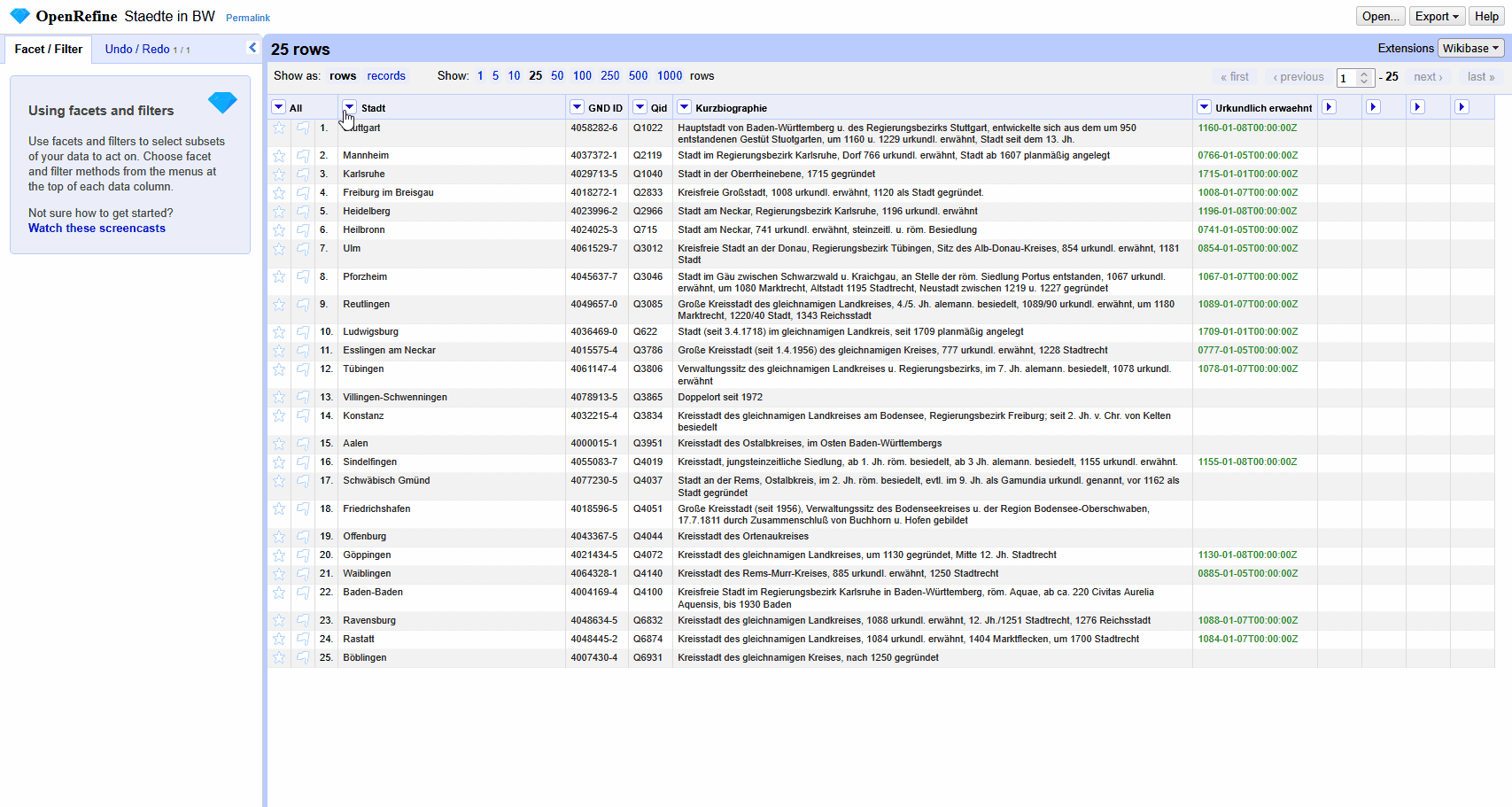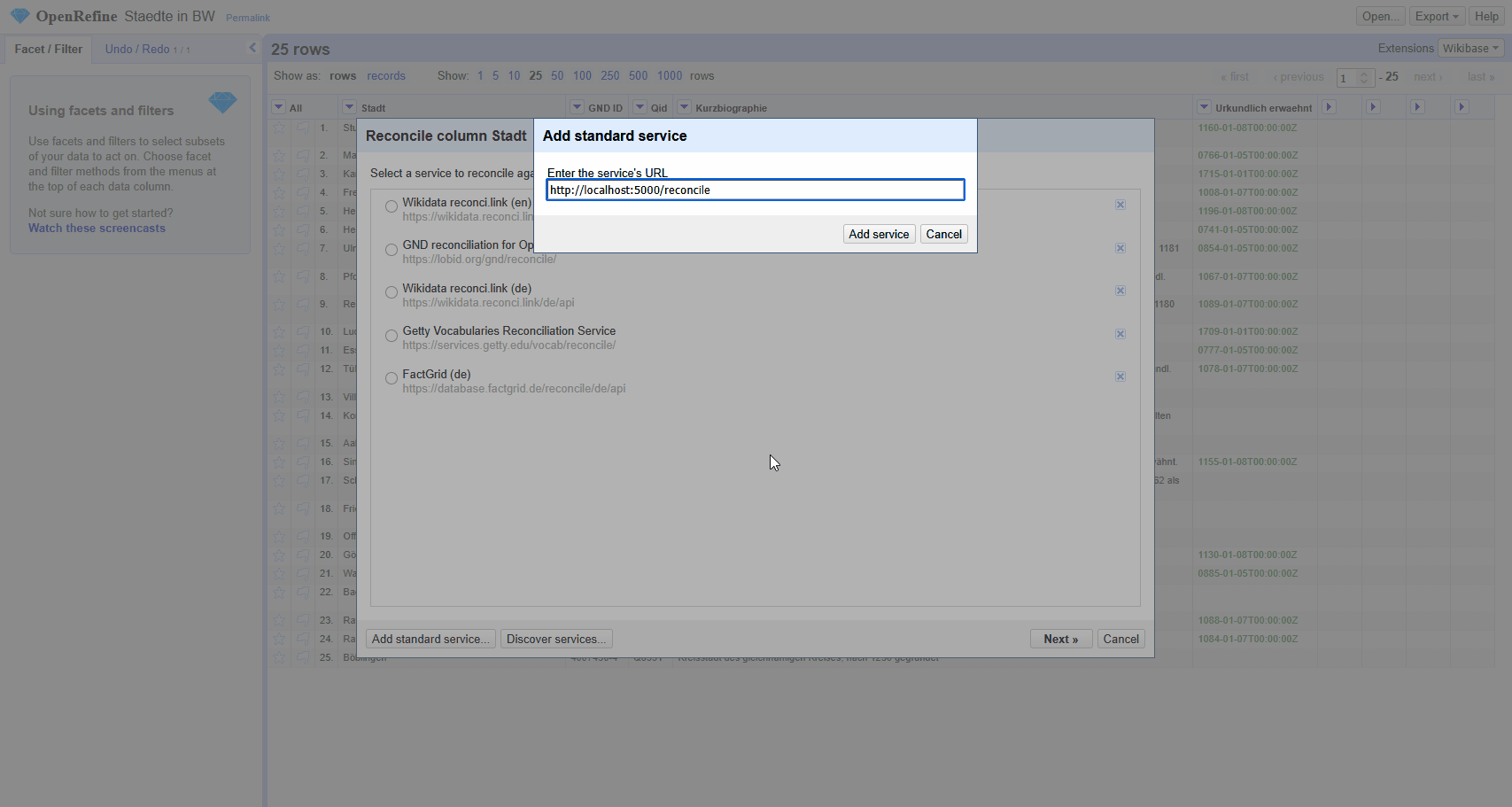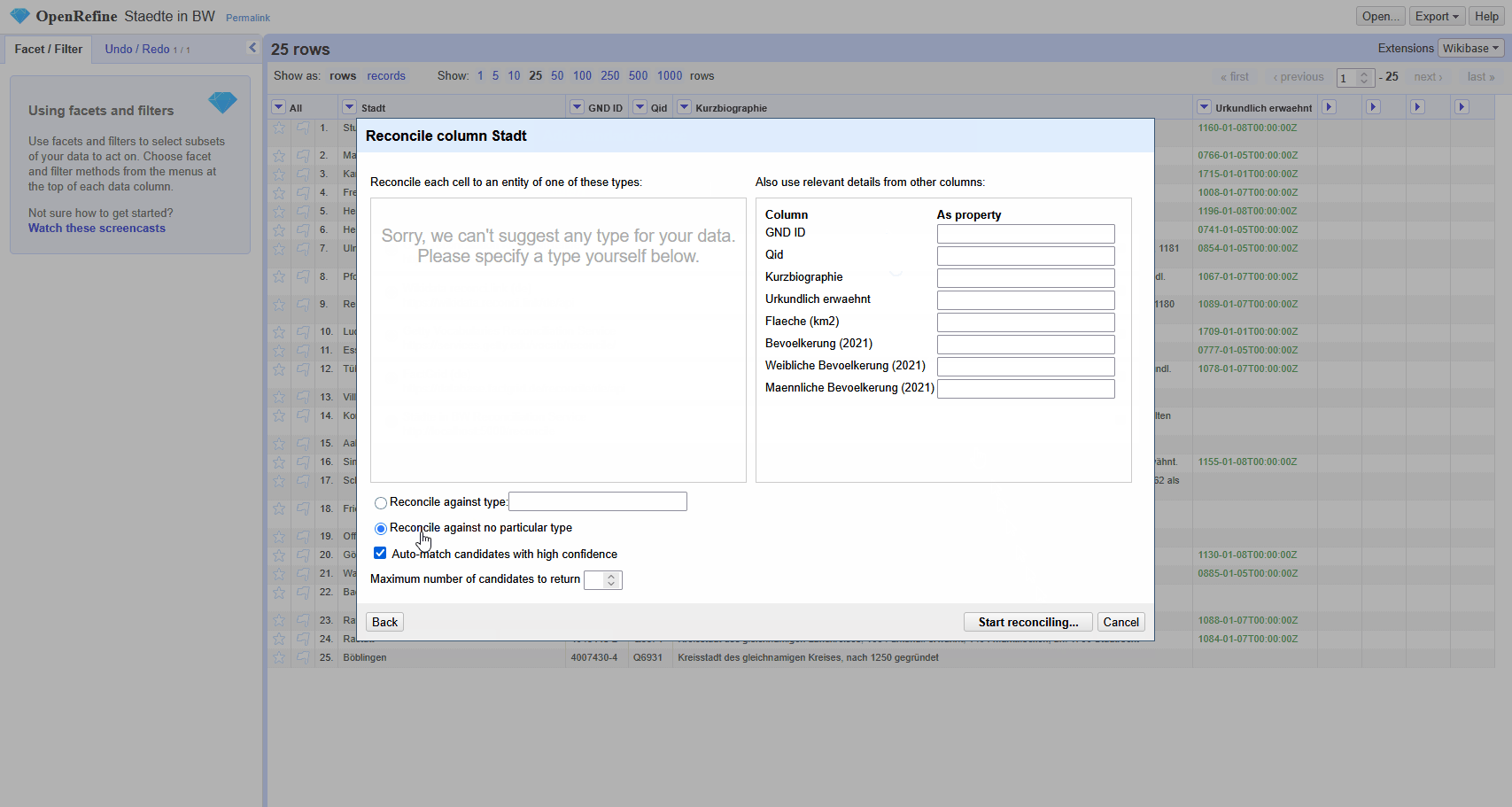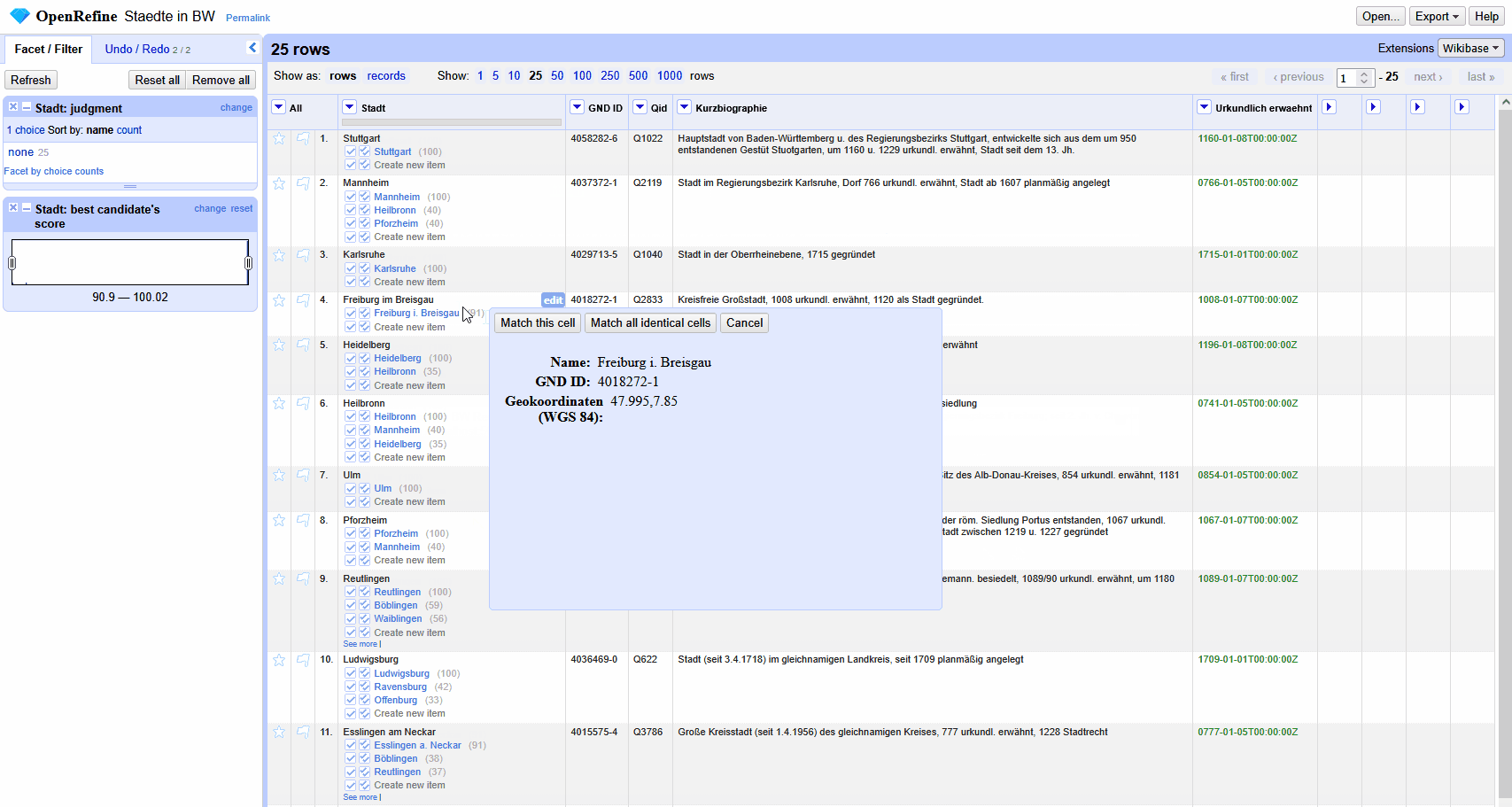
Eigene Skripte
Um Command Line Interfaces (CLIs) zu erstellen, gibt es in Python die Standardbibliothek argparse. Meistens möchte man aber “nur mal schnell” aus einer Python Funktion ein Werkzeug erstellen, welches von der Kommandozeile aufgerufen werden kann. Ein nützliches Python Projekt dafür ist typer.
Typer Hello World Beispiel
Ein einfaches “Hello World” Beispiel mit uv und Typer ist im folgenden Quellcode aus hello_world.py abgebildet.
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "typer",
# ]
# ///
import typer
def hello_world():
print("Hello World")
if __name__ == "__main__":
typer.run(hello_world)
Zu Beginn wird über Inline Metadaten definiert, dass das Skript mit Python 3.12 oder neuer ausgeführt werden soll und das Skript zusätzlich die externe Abhängigkeit typer benötigt.
Das Werkzeug uv unterstützt diese inline Metadaten, so dass zum Ausführen dieses Skriptes in einem Terminal lediglich uv run hello_world.py ausgeführt werden muss.
Das Werkzeug Typer übersetzt den CLI-Aufruf für die Python Funktion, und validiert und konvertiert dabei die Eingabedaten.
Typer Beispiel mit Parametern
Wir beginnen mit einem einfachen Beispiel.
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "typer",
# ]
# ///
import typer
def add(a, b):
print(a + b)
if __name__ == "__main__":
typer.run(add)
Die Funktion add soll zwei Parameter a und b miteinander addieren und dann ausgeben.
Zum Ausgeben des Ergebnisses verwenden wir die Funktion print.
Das Werkzeug typer erkennt automatisch die beiden Parameter a und b und meldet, wenn diese nicht gesetzt sind.
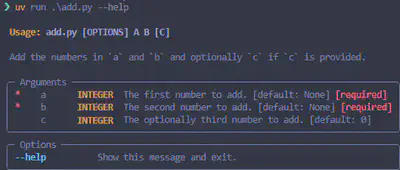
Unter uv run add.py --help erhalten wir einen Informationstext zur Benutzung unseres CLI-Tools.
Standardmäßig werden die Parameter als Text interpretiert. Mit so genannten Type Hints können wir Typer mitteilen, dass wir hier Zahlen erwarten.
def add(a: int, b: int):
print(a + b)
Es ist auch möglich, optionale Parameter wie c mit anzugeben.
def add(a: int, b: int, c: int = 0):
print(a + b + c)
Individuelle Konfigurationen können mit Type Annotations hinterlegt werden.
def add(a, b, c: Annotated[int, typer.Argument()] = 0):
print(a + b + c)
Mit den Annotationen lässt sich bei Bedarf der Text für die Hilfe weiter spezifizieren. Hier das fertige Skript mit ausführlicherem Hilfstext.
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "typer",
# ]
# ///
import typer
from typing_extensions import Annotated
def add(
a: Annotated[int, typer.Argument(help="The first number to add.")],
b: Annotated[int, typer.Argument(help="The second number to add.")],
c: Annotated[int, typer.Argument(help="The optionally third number to add.")] = 0,
):
"""
Add the numbers in `a` and `b` and optionally `c` if `c` is provided.
"""
print(a + b + c)
if __name__ == "__main__":
typer.run(add)
Das Praktische an Typer ist, dass man “nur zum Ausprobieren” lediglich die type hints und den Aufruf von Typer im Skript ergänzen muss. Bei Bedarf können ausführlichere Hilfstexte oder Validierungen hinterlegt werden, deren Ergebnis in Abbildung 3 gezeigt ist.
Zugriff von OpenRefine auf Python Skript
Von OpenRefine heraus, lässt sich mit Jython recht unkompliziert auf das externe Python Skripte zugreifen. Es muss lediglich der Pfad des Skriptes in dem Jython Snippet unten angepasst werden. Ggf. müssen auch noch Parameter für das Skript ergänzt werden.
import subprocess
script = "C:\\...\\python_script.py"
res = subprocess.check_output(
["uv", "run", script, "\""+value+"\""],
shell=True,
)
return res
Probleme beim Zugriff von OpenRefine auf Python Skripte
Der direkte Zugriff auf ein Skript ist erst einmal relativ performant, hat in der Praxis aber mehrere Probleme.
- Die korrekte Übergabe von Daten an das Skript via Parametern ist nicht ganz so einfach. Besonders, wenn die Daten größer sind ggf. Sonderzeichen enthalten, …
- Man ist selbst für die Fehlerbehandlung verantwortlich. Also dass die Skripte auch irgendwann beendet werden, bei zu langer Laufzeit abgebrochen werden, usw.
- Es wird lediglich Text zurückgegeben. Die Interpretation in ein bestimmtes Format muss dann in Jython oder in einem Nachbearbeitungsschritt erfolgen.
- Manche Skripte oder Tools müssen initial erst einmal Daten in den Arbeitsspeicher laden. Insbesondere bei Machine Learning Anwendungen kann das mehrere Sekunden dauern. Dies erfolgt bei jedem Skriptaufruf wieder erneut.
Daher ist es wesentlich stabiler stattdessen mit eigenen Web-APIs zu arbeiten.
Eigene Web-APIs mit FastAPI
Für Web-APIs gibt es etablierte und stabile Protokolle zum Austausch von Daten. Ähnlich wie mit Typer können wir mit FastAPI unsere Python-Funktionen als Web-API zur Verfügung stellen. Mit einem Server wie uvicorn sorgen wir dabei für eine Stabilität der angestoßenen Prozesse für die Abfragen.
Beispielcode für spaCy
Das folgende Skript lädt ein deutschsprachiges Modell von spaCy und berechnet über Word Embeddings die Ähnlichkeit bzw. hier die Distanz der beiden übergebenen Texte.
# /// script
# requires-python = ">=3.12,<3.13"
# dependencies = [
# "spacy",
# "typer",
# "de_core_news_lg @ https://github.com/explosion/spacy-models/releases/download/de_core_news_lg-3.8.0/de_core_news_lg-3.8.0.tar.gz",
# ]
# ///
import typer
import de_core_news_lg as model
def spacy_distance(a: str, b: str):
nlp = model.load()
doc_a = nlp(a)
doc_b = nlp(b)
dist = 1 - doc_a.similarity(doc_b)
print(dist)
if __name__ == "__main__":
typer.run(spacy_distance)
Das Skript hat den eindeutigen Nachteil, dass es bei jedem Aufruf das “große” Sprachmodell laden muss, was mehrere Sekunden dauert.
Hier im Vergleich das Skript spacy_distance_fastapi.py, welches die Funktionalität via FastAPI zur Verfügung stellt.
# /// script
# requires-python = ">=3.12,<3.13"
# dependencies = [
# "spacy",
# "fastapi",
# "uvicorn",
# "de_core_news_lg @ https://github.com/explosion/spacy-models/releases/download/de_core_news_lg-3.8.0/de_core_news_lg-3.8.0.tar.gz",
# ]
# ///
import de_core_news_lg as model
import uvicorn
from fastapi import FastAPI
app = FastAPI()
nlp = model.load()
@app.get("/distance")
def spacy_distance(a: str, b: str) -> float:
doc_a = nlp(a)
doc_b = nlp(b)
dist = 1 - doc_a.similarity(doc_b)
return dist
if __name__ == "__main__":
uvicorn.run("spacy_distance_fastapi:app", host="127.0.0.1", port=5000)
Die Verarbeitungspipeline für die Texte mit dem “großen” Sprachmodell wird außerhalb der Python Methode definiert, weshalb das Modell pro Aufruf nur einmal aufgerufen werden muss. Im Vergleich zum direkten Skriptaufruf, ist der Zugriff auf unsere lokale Web-API zwar etwas langsamer. Wir profitieren aber von der Müglichkeit ladeintensive Prozesse nur einmal beim Starten auszuführen, sowie von dem zusätzlichen Protokoll im Bereich Fehlerbehandlung, Validierung von Eingaben und Antworten.
Ähnlich wie bei Typer übernimmt FastAPI hier das Mapping der Benutzeranfrage auf die entsprechende Python Funktion. Gleich wie bei Typer werden Type Hints für das Mapping, die Dokumentation und die Validierung verwendet. Auch bei FastAPI kann die Dokumentation mit weiteren Annotationen erweitert und personalisiert werden.
Somit lassen sich mit FastAPI eigene Web-APIs ähnlich leicht erstellen, wie einfache Python Skripte mit Typer. Ausführliche Beispiele stehen im Anhang bzw. als GitHub Gist unter spacy_fastapi.py und rapidfuzz_fastapi.py zur Verfügung.
Von OpenRefine heraus kann man via Jython auf die (lokalen) Web-APIs zugreifen.
Zugriff via GET
Web-APIs unterscheiden für den Abruf von Daten zwischen GET- und POST-Requests (Anfragen). Für GET-Requests gibt es in OpenRefine die Möglichkeit den Dialog Add column by fetching URLs zum Nachladen von Daten zu verwenden.
"http://localhost:5000/ner?text=" + escape(value, "url")
Hier kann man mit einfachem GREL die benötigte URL zusammen bauen. Man sollte jedoch daran denken, die Parameter mit escape für die URL kompatibel aufzubereiten.
In Abbildung 4 ist der Dialog aus 18 Nachladen von Geokoordinaten gezeigt.

Möchte man eine Web-API z.B. von einem Facet oder einem Clustering-Dialog heraus aufrufen, benötigt man dafür das folgende Jython-Snippet um einen validen GET-Request zu erstellen.
import json, urllib, urllib2
url = "http://localhost:5000/ner"
request_data = urllib.urlencode({
"text": value.encode("utf-8"),
})
response = urllib2.urlopen(url + "?" + request_data)
return json.dumps(json.load(response), ensure_ascii=False)
Zugriff via GET und Form
Manche Web-APIs erwarten einen GET-Request mit zusätzlichem Nutzdaten z.B. aus einem Formular. Das lässt sich in Jython / Python 2.7 mit folgendem Snippet umsetzen.
import json, urllib, urllib2
url = "http://localhost:5000/ner"
request_data = urllib.urlencode({
"text": value.encode("utf-8"),
})
response = urllib2.urlopen(url, request_data)
return json.dumps(json.load(response), ensure_ascii=False)
Der Unterschied zum letzten Beispiel ist, dass request_data als zusätzliche Nutzdaten mit einem Komma getrennt an urllib2 übergeben werden, anstatt sie mit an die URL zu kodieren.
Zugriff via POST
Der in den Beispielen im Anhang verwende Use-Case ist das Verwenden von POST-Requests. Hier werden die Nutzdaten als JSON kodiert an den Request angehängt. Das macht die Kodierung der Daten in der Anfrage komplexer, gleichzeitig aber die Übermittlung stabiler.
import json, urllib, urllib2
url = "http://localhost:5000/ner"
request_data = json.dumps({
"text": value.encode("utf-8"),
})
request = urllib2.Request(
url,
request_data,
{"Content-Type": "application/json"},
)
response = urllib2.urlopen(request)
return json.dumps(json.load(response), ensure_ascii=False)
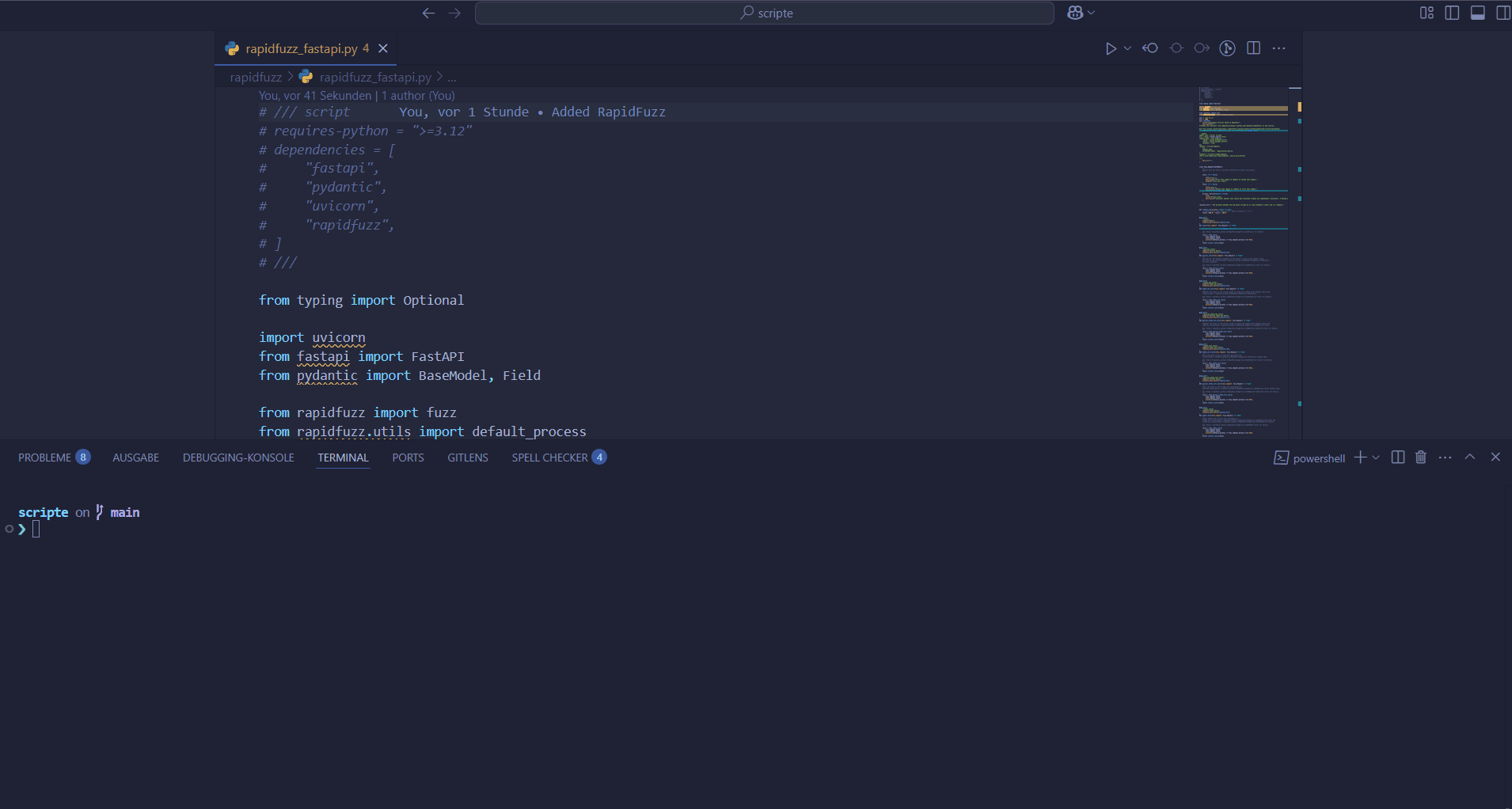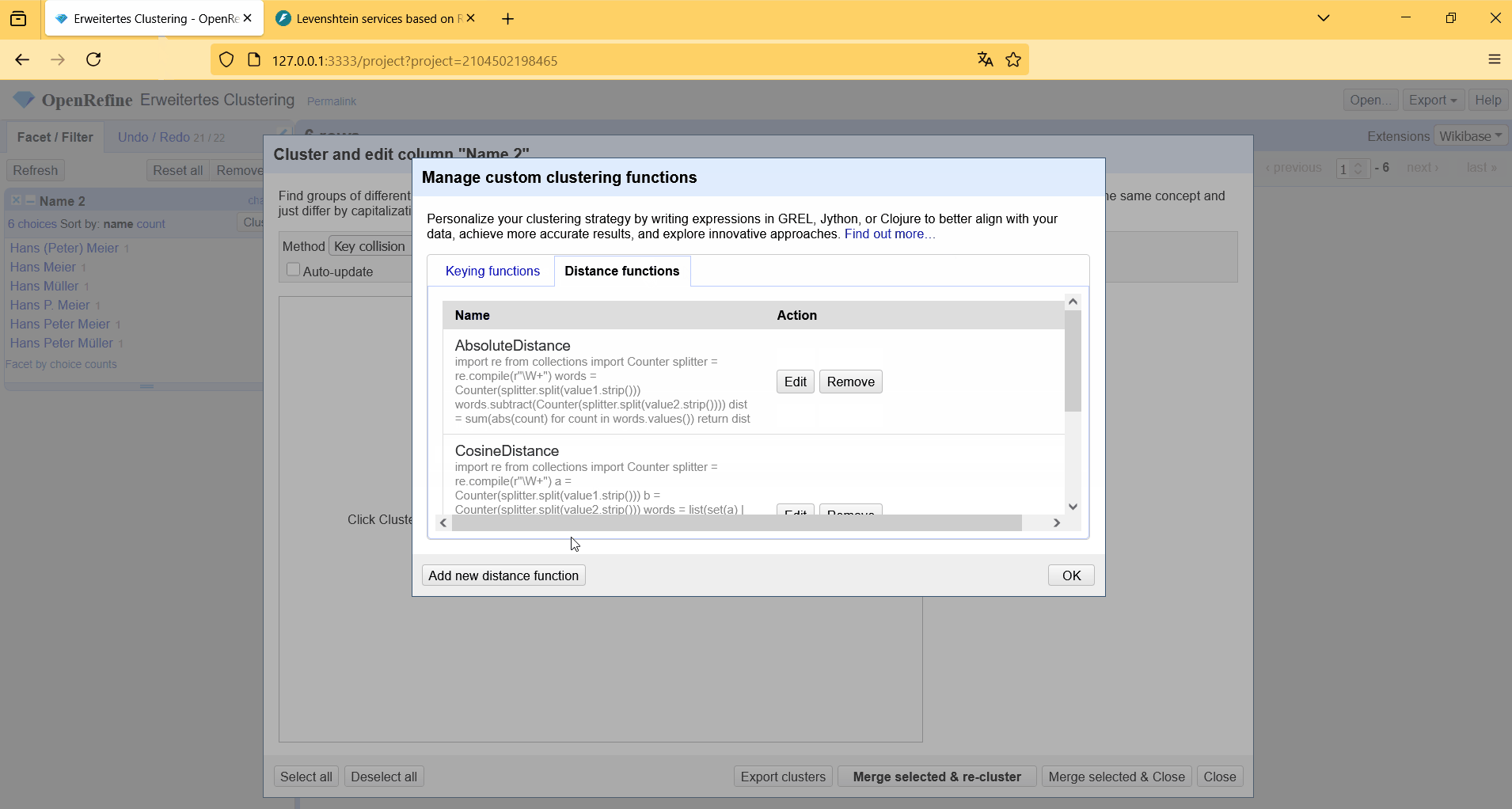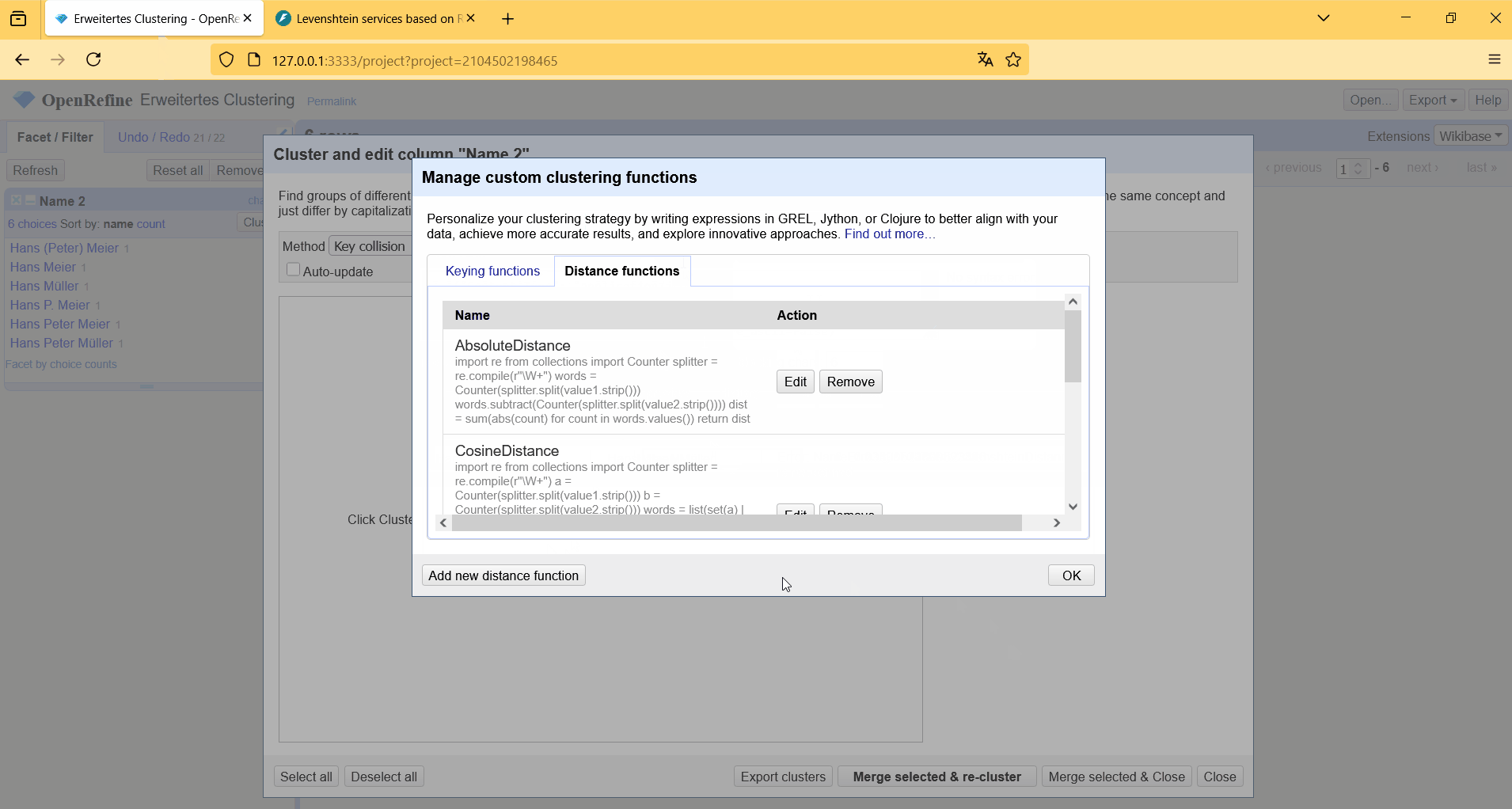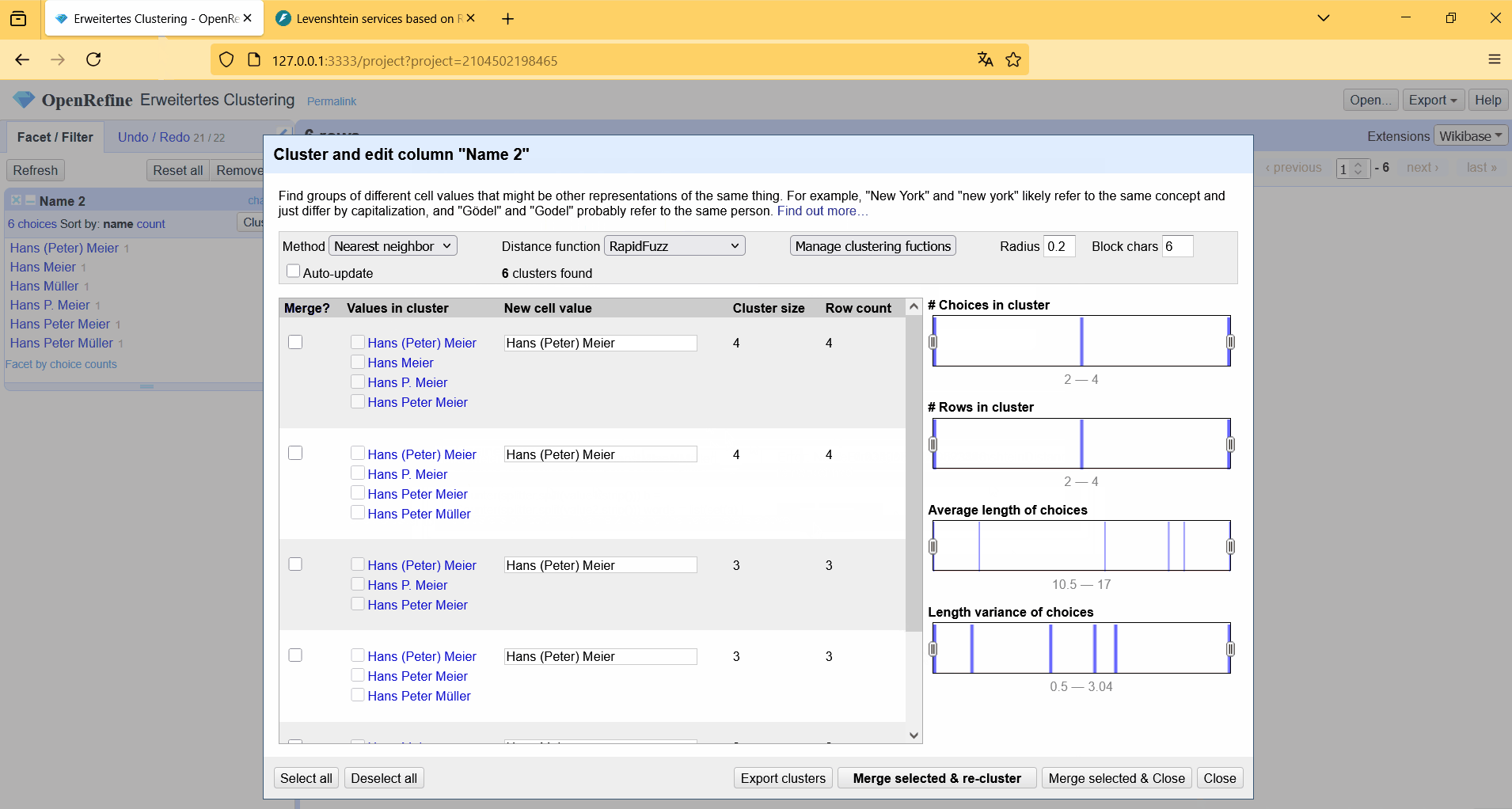
Der komplette Workflow vom Starten des Web-Service, bis zur Verwendung von RapidFuzz als eigene Clustering Methode in OpenRefine ist in dem Screencast in Abbildung 5 gezeigt.
Fazit
Kleinere Skripte mit Jython / Python 2.7 in OpenRefine sind möglich, jedoch gerade beim Clustering oder bei der Nachnutzung von externen Python Projekten problematisch.
Mit Typer und FastAPI lassen sich aus Python Funktionen heraus schnell CLI-Tools oder Web-APIs erstellen. Die beiden Werkzeuge ermöglichen es sowohl mit wenig Aufwand Prototypen zu erstellen, als auch diese zu dokumentierten praktischen Tools zu erweitern.
Mit uv sind die Hürden für das Erstellen von indivduellen Python Umgebungen für einzelne Skripte sehr stark gesenkt worden. Das reduziert nicht nur den Entwicklungsaufwand, sondern erleichtert auch die Nachnutzung von Skripten für Nutzerinnen und Nutzer.
Mit der Kombination aus Jython, uv und wahlweise Typer oder FastAPI lassen sich dadurch modernste Python Anwendungen direkt mit OpenRefine verbinden.
Anhang
FastAPI Wrapper für spaCy
FastAPI Wrapper für RapidFuzz
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.