Workshop - XML in OpenRefine importieren und exportieren
 Folie - XML in OpenRefine importieren und exportieren
Folie - XML in OpenRefine importieren und exportierenIn diesem Tutorial beschäftigen wir uns mit dem Laden von XML in OpenRefine und dem Exportieren nach XML mit Templating.
Einführung
Templating in der OpenRefine Dokumentation.
Templating im OpenRefine Wiki.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
Die als XML abgekürzte “Extensible Markup Language” kann sehr komplexe Datenformate abbilden. Von Textdokumenten über Grafikdaten zu Geodaten. Im GLAM Bereich begegnet uns XML in Standards wie EAD, METS, MODS, RiC, TEI, usw.
Zur Abbildung der komplexen Strukturen in XML verwendet OpenRefine die im Workshop schon besprochenen Records. Damit können aber nur baumartige Strukturen abgebildet werden und keine komplexen Netzwerke.
Um zu verstehen, wie OpenRefine XML einliest und ausgeben kann, verwenden wir exemplarisch ein einfaches Format.
<?xml version="1.0" encoding="utf-8"?>
<kabinett title="Kretschmann III">
<person gnd-id="143926683" sex="m" birthday="1948-05-17" birthplace="Spaichingen">
<name>Kretschmann, Winfried</name>
<links>
<link>http://dbpedia.org/resource/Winfried_Kretschmann</link>
<!-- ... -->
</links>
</person>
<!-- ... -->
</kabinett>
Das sind die Daten der Politiker des Kabinetts Kretschmann III, diesmal im XML Format. Die Personendaten sind teilweise in Attributen und teilweise als separates Element angelegt.
Die Links auf weitere “Profile” sind als Sammlung unterhalb des <person> Elementes angelegt.
Aufgabe 1: XML Laden
Wir laden die folgende Datei in ein OpenRefine-Projekt.
Kretschmann III als XML💾 Wir benötigen die folgende Datei (Rechtsklick und “Ziel speichern unter…”):
Der Import von XML-Daten beginnt mit einem anderen Dialog, als wir es gewohnt sind.
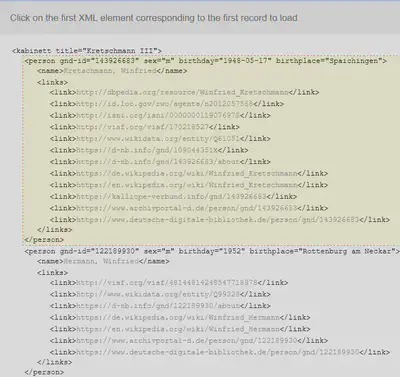
Wie in Abbildung 1 gezeigt fragt OpenRefine nach dem ersten XML Element, welches als Record geladen werden soll.
Wir wählen hier das <person> Element aus, da wir die Daten zu den Personen laden möchten.
Die restlichen Daten, wie zum Beispiel das <kabinett> Element mit dem title Attribut werden dann verworfen.
In Abbildung 2 ist das Projekt direkt nach dem Import abgebildet. Wir sind im “Record” Modus und aus jeder Person wurde ein “Record”. Die Links sind auf mehrere Zeilen aufgeteilt.
Interessant ist die automatische Benennung der Spalten:
- Das Attribut
gnd-idam Element<person>wurde in die Spalteperson - gnd-idgeladen. - Das Element
<name>mit dem XML Pfad/kabinett/person/namewurde in die Spalteperson - namegeladen. - Die Linksammlung mit dem XML Pfad
/kabinett/person/links/linkwurde in die Spalteperson - links - linkgeladen.
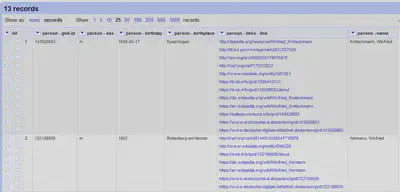
Durch diese automatische Benennung lässt sich nachvollziehen, woher die Daten stammen und wie sie zusammengehören. Es bedeutet aber auch, dass wir die Spalten alle manuell umbenennen müssen.
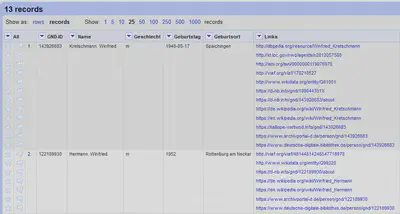
Aufgabe: Benennen Sie die Spalten wie in Abbildung 3 gezeigt um.
Aufgabe 2: XML exportieren (einfach)
Theoretisch könnten wir die Daten im Projekt jetzt mit weiteren Daten anreichern, umformatieren… Diesen Part überspringen wir und beschäftigen uns direkt damit, wie wir die Daten wieder als XML exportieren können.
Unser Zielformat sieht wie in folgendem Beispiel aus:
<?xml version="1.0" encoding="utf-8"?>
<personen>
<person>
<gnd-id>143926683</gnd-id>
<name>Kretschmann, Winfried</name>
<geschlecht>m</geschlecht>
<geburtstag>1948-05-17</geburtstag>
<geburtsort>Spaichingen</geburtsort>
</person>
<!-- ... -->
</personen>
Wir wollen also die Personendaten in einzelne Elemente speichern und erstmal auf die Links verzichten. Dafür wechseln wir in OpenRefine in den “Rows” Modus und filtern die zusätzlichen Link Zeilen via “GND-ID" "Facet" "Customized facets" "Facet by blank (null or empty string)”.
Anschließend gehen wir auf “Export" "Templating…” um den in Abbildung 4 gezeigten Dialog aufzurufen.
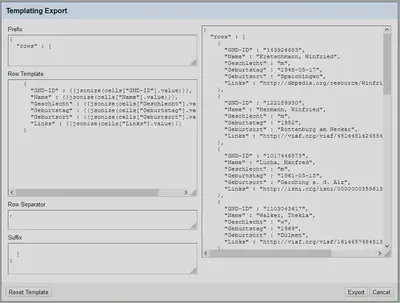
Dieser Dialog besteht aus fünf Teilen:
- Das “Prefix”, also der Text, der zu Beginn steht.
- Das “Row Template”, also das Template für die einzelnen Zeilen.
- Der “Row Separator”, also das Trennzeichen zwischen den einzelnen Zeilen.
- Das “Suffix”, also der Text, der am Ende steht.
- Eine Vorschau auf der rechten Seite.
Initial wird ein Template zum Erzeugen von JSON geladen.
Im Template Feld sind GREL-Ausdrücke in geschweiften Klammern {{...}} zu sehen, die die Werte in den einzelnen Feldern mit der Funktion jsonize() in ein kompatibles Format umwandeln.
Für die Generierung von XML gehen wir ähnlich vor.
Prefix
Zu Beginn benötigen wir die XML Deklaration und das Wurzelelement <personen>, welche wir in das Feld “Prefix” schreiben.
<?xml version="1.0" encoding="utf-8"?>
<personen>
Suffix
Das Wurzelelement schließen wir im Feld “Suffix” und fügen davor zur besseren Lesbarkeit noch eine Leerzeile (Zeilenumbruch) hinzu.
</personen>
Row Separator
Um die einzelnen Zeilen zu separieren verwenden wir ebenfalls eine Leerzeile (Zeilenumbruch).
Row Template
Der aufwendigste Part ist die Erstellung eines Templates für die einzelnen Zeilen im Feld “Row Template”. Hierfür können wir in einem ersten Versuch die Vorlage des Zielformates in das Feld kopieren und die einzelnen Werte mit Variablen (Spaltenname) versehen.
<person>
<gnd-id>${GND-ID}</gnd-id>
<name>${Name}</name>
<geschlecht>${Geschlecht}</geschlecht>
<geburtstag>${Geburtstag}</geburtstag>
<geburtsort>${Geburtsort}</geburtsort>
</person>
Die Variante mit Variablen funktioniert und ist gut zu lesen. Sie hat jedoch den Nachteil, dass einzelne Sonderzeichen in den Feldern (< oder > ) die Struktur des XML Dokumentes zerstören können.
Um das zu verhindern, gibt es in GREL die Funktion escape().
Aufgabe: Schreiben sie die Vorlage so um, dass statt der Variablen analog zu dem JSON Template GREL Ausdrücke mit escape() verwendet werden.
Lösung:
<person>
<gnd-id>{{escape(cells["GND-ID"].value, "xml")}}</gnd-id>
<name>{{escape(cells["Name"].value, "xml")}}</name>
<geschlecht>{{escape(cells["Geschlecht"].value, "xml")}}</geschlecht>
<geburtstag>{{escape(cells["Geburtstag"].value, "xml")}}</geburtstag>
<geburtsort>{{escape(cells["Geburtsort"].value, "xml")}}</geburtsort>
</person>
Aufgabe 3: XML exportieren (Records)
In Aufgabe 2 haben wir die Baumstruktur des Dokumentes ignoriert, also die Links weggelassen. Diesmal wollen wir die Links jedoch mit ausgeben. Dafür deaktivieren wir das in Aufgabe 2 erstellte Facet und wechseln in den “Record” Modus.
Unser Zielformat sieht wie folgt aus:
<?xml version="1.0" encoding="utf-8"?>
<personen>
<person>
<gnd-id>143926683</gnd-id>
<name>Kretschmann, Winfried</name>
<geschlecht>m</geschlecht>
<geburtstag>1948-05-17</geburtstag>
<geburtsort>Spaichingen</geburtsort>
<links>
<link>http://dbpedia.org/resource/Winfried_Kretschmann</link>
<!-- ... -->
</links>
</person>
<!-- ... -->
</personen>
Es unterscheidet sich also lediglich durch das zusätzliche Element <links>.
Leider gibt es bei den Vorlagen in OpenRefine keine direkte Unterstützung von “Records”, so dass wir uns mit GREL behelfen müssen. Wir bauen also das komplette Template durch eine Verkettung von Textschnippseln in GREL zusammen. Dafür verwenden wir die Kontrollstrukturen if und forEach.
Hier ist die allgemeine Idee für unseren Algorithmus:
Wir verarbeiten immer nur die erste Zeile eines Records.
if(row.index - row.record.fromRowIndex == 0, "<person>\n" + ... + "</person>", "")Wir geben alle Spalten mit nur einer gefüllten Zeile im Record direkt aus.
"<gnd-id>" + escape(cells["GND-ID"].value, "xml") + "</gnd-id>\n"Wir zählen Spalten mit mehr als einer Zeile im Record zeilenweise mit
forEachauf.forEach(row.record.cells["Links"].value, link, "<link>" + escape(link, "xml") + "</link>") .join("\n")
Aufgabe: Erstellen Sie mit GREL ein Template, welches zusätzlich zu den Daten aus Aufgabe 1 auch die Links mit ausgibt.
Hinweis: Wir verzichten in diesem GREL Ausdruck auf Leerzeichen zur Formatierung des XML zur Einrückung der einzelnen Elemente.
Wir haben die Erfahrung gemacht, dass die Lesbarkeit der GREL Ausdrücke darunter leidet.
Einfacher ist es, bei Bedarf das XML anschließend in einem Editor wie Notepad++ oder Visual Studio Code mit den entsprechenden XML Erweiterungen automatisch formatieren und dabei auch gleich noch validieren zu lassen.Lösung:
{{
if(row.index - row.record.fromRowIndex == 0,
"<person>\n"
+ "<gnd-id>" + escape(cells["GND-ID"].value, "xml") + "</gnd-id>\n"
+ "<name>" + escape(cells["Name"].value, "xml") +"</name>\n"
+ "<geschlecht>" + escape(cells["Geschlecht"].value, "xml") + "</geschlecht>\n"
+ "<geburtstag>" + escape(cells["Geburtstag"].value, "xml") + "</geburtstag>\n"
+ "<geburtsort>" + escape(cells["Geburtsort"].value, "xml") + "</geburtsort>\n"
+ "<links>\n"
+ forEach(row.record.cells["Links"].value, link, "<link>" + escape(link, "xml") + "</link>")
.join("\n")
+ "\n</links>\n"
+ "</person>",
""
)
}}
Fazit
Wir haben für diesen Workshop bewusst ein einfach strukturiertes XML Beispiel erstellt um direkt zu sehen, wie OpenRefine die XML Struktur verarbeitet und XML erstellen kann.
Üblicherweise sind XML Dateien weitaus tiefer strukturiert und es dauert entsprechend länger, bis die Daten in OpenRefine passend benannt und sortiert sind.
Auch der Export ist oft weitaus komplexer, zum Beispiel wenn Felder optional leer sein können oder es mehrere Verschachtelungen in den Records gibt.
Jedoch sind die Strategien zur Lösung dieser Probleme (“Sortieren & Umbenennen” bzw. “if und forEach”) die gleichen wie hier im Beispiel besprochen.
Im nächsten Teil beschäftigen wir uns mit dem erweiterten Datenabgleich zwischen OpenRefine und der Gemeinsamen Normdatei via des lobid API.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.