Workshop - Die Welt der Facets in OpenRefine
 Folie - Die Welt der Facets in OpenRefine
Folie - Die Welt der Facets in OpenRefineNachdem wir uns im Workshops für Einsteiger hauptsächlich mit den Text Facets in OpenRefine beschäftigt haben, betrachten wir in diesem Tutorial weitere nützliche Facets.
Einführung
Facets in der OpenRefine Dokumentation.
Reconciliation Facets in der OpenRefine Dokumentation.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
Vorbereitung: Projekt erstellen
Wir verwenden das im Tutorial 12 Daten zwischen Projekten abgleichen erstellte Projekt “Staedte in BW”.
Aufgabe 1: Datentypen anpassen
Der Grundzustand des Projektes ist in Abbildung 1 gezeigt.
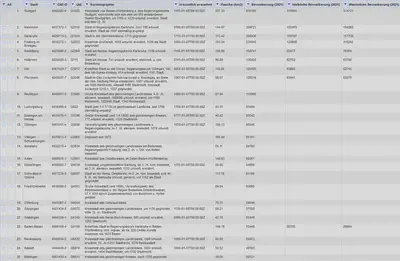
An der schwarzen Farbe der Spalteninhalte erkennen wir, dass wir es hier ausschließlich mit Textspalten zu tun haben. Da wir in diesem Tutorial Facets für verschiedene Datentypen kennen lernen wollen, passen wir die Datentypen der einzelnen Spalten an.
Hierfür gibt es in OpenRefine schon Befehle, die wir im Spaltenmenü finden “…“ "Edit cells" "Common Transforms" ”…”
Aufgabe: Wir passen die Datentypen in den folgenden Spalten an:
- Urkundlich erwaehnt: Datum (
toDate) - Flaeche (km2): Zahl (
toNumber) - Bevoelkerung (2021): Zahl (
toNumber) - Weibliche Bevoelkerung (2021): Zahl (
toNumber) - Maennliche Bevoelkerung (2021): Zahl (
toNumber)
Das Ergebnis sollte dann aussehen wie in Abbildung 2.
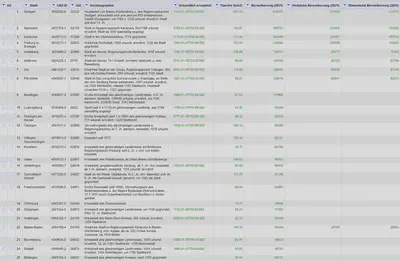
Aufgabe 2: All Facets
In der “All” Spalte gibt es Facets, die auf den ganzen Datensatz angewendet werden können. Neben den schon bekannten Facets zum Filtern von mit Sternen oder Flaggen markierten Zeilen sowie komplett leeren Zeilen gibt es auch Facets zum Filtern von leeren Einträgen in Spalten oder Records. In Abbildung 3 sind die beiden Facets für “Blank value per column” und “Non-blank value per column” gezeigt. Mit diesen Facets lassen sich schnell und übersichtlich Zeilen filtern, ohne das “Facet by blank” für jede Spalte separat aufzurufen.
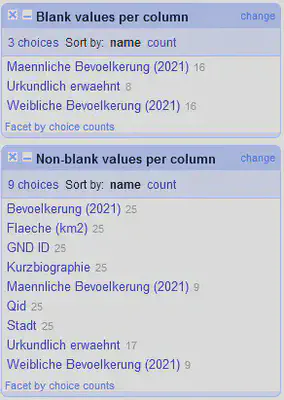
Aufgabe: Überprüfen Sie die folgende Aussage.
“Alle Orte in diesem Datensatz ohne Angabe zum männlichen Bevölkerungsanteil haben auch keine Angabe zum weiblichen Bevölkerungsanteil.”
Aufgabe 3: Null oder Leer
Bei den einzelnen Spalten gibt es drei Facets zur Identifikation von leeren Zeilen. Das Äquivalent zu den in Aufgabe 2 vorgestellten Facets ist das “Facet by blank (null or empty string)”, welches in Abbildung 4 abgebildet ist. Das Facet wurde geöffnet mit “Urkundlich erwaehnt" "Facet" "Customized facets" "Facet by blank (null or empty string)”.
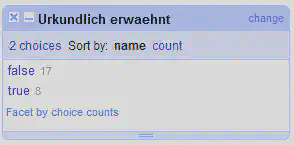
Aufgabe: Öffnen Sie auf der Spalte “Urkundlich erwaehnt” zusätzlich die Facets “Facet by null” und “Facet by empty string”. Worin unterscheiden sich die drei Facets?
Lösung:
OpenRefine unterscheidet zwischen nichts (null) und einem leeren Text (""), der ja zumindest vom Typ Text ist. Da wir aber häufig null und "" gemeinsam behandeln wollen, gibt es zusätzlich blank, was null und "" zusammenfasst.
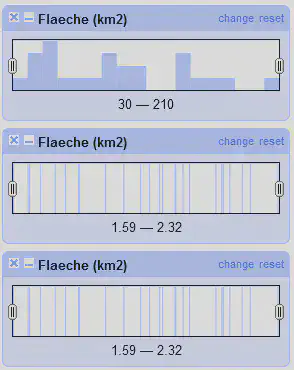
Aufgabe 4: Numeric Facets
OpenRefine bietet unterschiedliche visuelle Darstellungen für Zahlen in Facets an. In Abbildung 5 ist die Histogrammansicht gezeigt. Auf der X-Achse ist der Wertebereich abgebildet und auf der Y-Achse die Häufigkeit des entsprechenden Wertes. Der angezeigte Bereich lässt sich mit Schiebern an den Seiten einschränken.
Zusätzlich zu dem normalen “Numeric Facet” gibt es bei den “Customized Facets” noch eine logarithmische Darstellung (“Numeric log facet”) und eine begrenzte logarithmische Darstellung (“1-boundet numeric log facet”).
Eine andere Darstellung ist das “Scatterplot facet”, welches zuerst ein Streudiagramm über alle numerischen Spalten anzeigt (Abbildung 6) und durch Auswahl eines Streudiagramms dieses in die Facet Ansicht übernimmt (Abbildung 7).
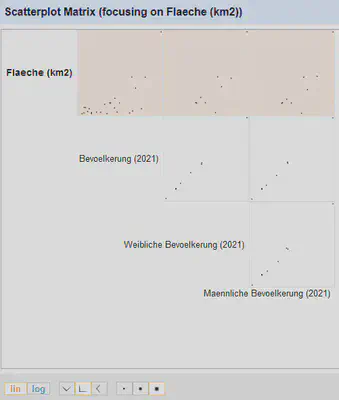
In dem Streudiagramm in Abbildung 7 lassen sich auch Werte und Bereiche mit der Maus auswählen und danach filtern.
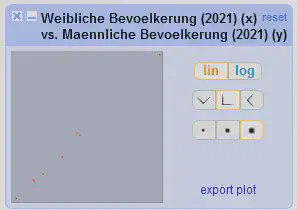
Aufgabe: In dem Datensatz gibt es laut Streudiagramm eine Stadt mit einem leichten “Männerüberschuss”. Um welche Stadt handelt es sich dabei?
Lösung:
Bei der Stadt handelt es sich um Karlsruhe.
Aufgabe 5: Timeline (und Custom) Facets
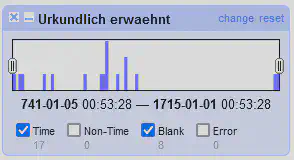
Es gibt ein separates Timeline Facet, welches auf eine Spalte vom Typ Datum (“date”) angewendet werden kann. Wie in Abbildung 8 zu sehen, ist das ähnlich wie beim “Numeric facet” ein Histogramm, nur dass die Daten auf der X-Achse nach Datum geordnet sind.
Da das bei Jahreszahlen auch recht schnell unübersichtlich wird, können wir so ein Facet auch selbst erstellen. Wir gehen dazu auf “Urkundlich erwaehnt" "Facet" "Custome Numeric Facet…” und verwenden den folgenden GREL-Ausdruck um das in Abbildung 9 gezeigte Facet zu erstellen.
value.datePart("year")
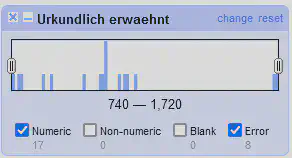
Aufgabe: Erstellen Sie ein Facet mit den Differenzen für “weibliche - männliche” Bevölkerung.
Lösung:
Dafür benötigen wir ein “Custom Numeric Facet” mit dem folgenden GREL-Ausdruck:
row.cells["Weibliche Bevoelkerung (2021)"].value -
row.cells["Maennliche Bevoelkerung (2021)"].value
Da wir in dem GREL Ausdruck die Spalten direkt aufrufen, ist es egal von welcher Spalte aus wir das Facet erstellen.
Aufgabe 6: Text Facets
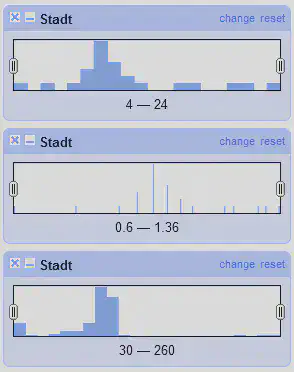
Es gibt neben dem “normalen” Text Facet auch noch weitere Facets zum Umgang mit Text. In Abbildung 10 sind untereinander das “Text length facet”, das “Log of text length facet” und das “Unicode char-code facet” gezeigt.
Ziemlich hilfreich bei Texten ist auch das in Abbildung 11 gezeigte “Word Facet”, welches alle in der Spalte vorkommenden Worte aufzählt.
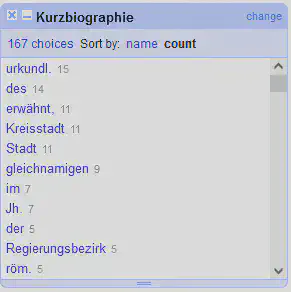
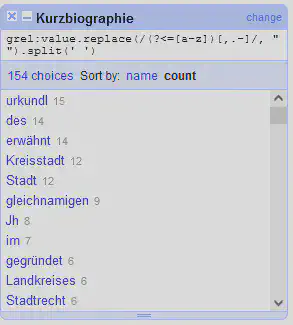
In Abbildung 11 ist zum Beispiel bei “erwähnt,” zu sehen, dass das normale Wort Facet auch Satzzeichen berücksichtigt. Möchte man das vermeiden, so kann dies durch einen Klick auf das blaue “change” im Kopfbereich des Facets angepasst werden. Wir passen den GREL-Ausdruck wie folgt an und erhalten das in Abbildung 12 gezeigte Facet.
value.replace(/(?<=[a-z])[,.-]/, " ").split(' ')
Aufgabe: Erstellen Sie auf der Spalte “Kurzbiographie” ein Facet, welches alle darin vorkommenden Jahreszahlen darstellt.
Lösung:
Dafür benötigen wir ein “Custom Text Facet” mit dem folgenden GREL-Ausdruck:
value.find(/\d{3,4}/)
Aufgabe 7: Facets für Reconciliation
Es gibt spezielle Facets zur Unterstützung von Reconciliation Vorgängen. Zwei davon (“Jugment action type” und “Best candidate’s score”) werden automatisch geladen.
Es können weitere Facets nachgeladen werden. Dafür starten wir einen Reconciliation Vorgang über “Stadt" "Reconcile" "Start Reconciling” und verwenden als “Service” den “GND reconciliation for OpenRefine” Service von lobid (siehe 06 Reconciling mit OpenRefine und der GND für die grundlegende Einrichtung und Benutzung des Dienstes).
Wir suchen nach einem “Geografikum” und lassen gut passende Treffer automatisch auswählen. Die Einstellungen sind in Abbildung 13 abgebildet.
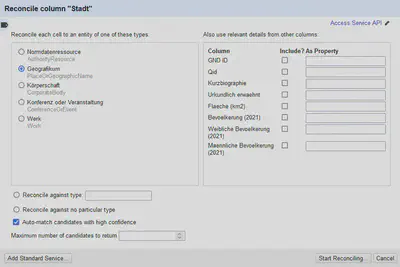
Über “Stadt" "Reconcile" "Facets" ”…" können wir dann die restlichen Facets nachladen.
Gruppe 1: Entscheidung
- By judgment (default)
- Jugment action type
- Jugment action timestamp
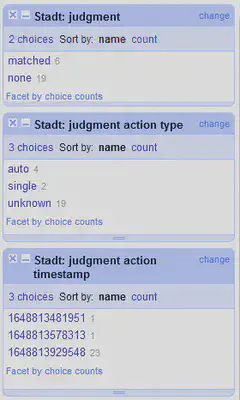
In der Gruppe 1 sind Facets zu den getroffenen Entscheidungen zu finden. Hier kann danach gefiltert werden, ob für eine Zeile schon eine Entscheidung getroffen wurde, ob die Entscheidung automatisch oder manuell getroffen wurde und sogar zu welchem Zeitpunkt (Zeitstempel) die Entscheidung getroffen wurde.
Gruppe 2: Treffer
- Best candidate’s score (default)
- Best candidate’s type match
- Best candidate’s name match
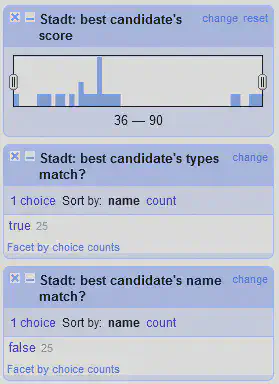
Die zweite Gruppe bezieht sich auf die Treffer und zwar immer nur auf den “besten” Treffer. Hier gibt es das Standard Facet mit der Bewertung des Treffers durch den Reconciliation Service. Außerdem gibt es noch zwei Facets, welche nützlich sind, wenn man iterativ mehrere Reconciliation Versuche auf einer Spalte durchführt und dabei mit und ohne Typisierung sucht.
Gruppe 3: Treffer Ähnlichkeit
- Best candidate’s name edit distance
- Best candidate’s name work similarity
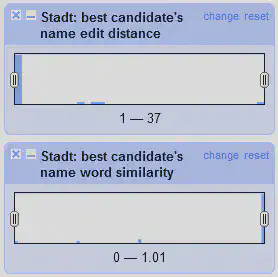
Der Algorithmus zur Auswahl von Treffern durch den Reconciliation Service ist häufig nicht transparent oder direkt nachvollziehbar. Daher lassen sich in OpenRefine zusätzliche Facets laden, die die Ähnlichkeit des Spalteninhalts mit dem jeweils besten Treffer anzeigen.
Die Editierdistanz basiert auf der Levenshtein Distanz, die wir schon in 05 Daten mit OpenRefine clustern kennen gelernt haben. Die Wortähnlichkeit hingegen wird berechnet, indem die Anzahl der übereinstimmenden Wörter ohne Stoppwörter zwischen Zellinhalt und bestem Treffer gezählt und normalisiert wird. Der Wertebereich geht dabei von 0 für keine Ähnlichkeit bis 1 für vollkommene Übereinstimmung.
Gruppe 4: Treffer Typ
- Best candidate’s types
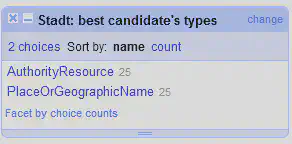
Die Liste der Typen, die sich aus dem jeweils besten Treffer für die einzelnen Zeilen ergeben.
Aufgabe: Beim Erstellen des Tutorials sind vier Städte automatisch mit einem Treffer gematcht worden. Ein Treffer ist jedoch falsch. Überlegen Sie, mit welcher Facet Kombination Sie diesen falschen Treffer schnell isolieren können.
Lösung:
Eine mögliche Kombination wäre im Facet “Jugment action type” den Wert auto auszuwählen und im Facet “Best candidate’s name edit distance” auf eine Distanz größer 1 zu filtern.
Der falsch zugeordnete Treffer ist dann “Freiburg im Breisgau”.
Da sich die Implementierung der Suchstrategie im lobid Reconciliation Server ändern kann, ist es möglich, dass Sie andere Ergebnisse erhalten.
Aufgabe 8: Duplikate
Das Duplikate Facet haben wir bewusst übersprungen und an das Ende verschoben.
Über “Urkundlich erwaehnt" "Facet" "Customized facets" "Duplicates facet” können wir uns Zeilen anzeigen lassen, deren Werte mehr als einmal vorkommen. Wir können hier aber keine Duplikate auswählen, markieren oder wie beim Clustern mit Ungenauigkeiten arbeiten.
Aufgabe: Überlegen Sie sich, wo das Duplikate Facet sinnvoll eingesetzt werden kann.
Mögliche Lösung:
Im FDMLab nutzen wir das Facet zur schnellen Überprüfung, ob zum Beispiel eine ID-Spalte nur eindeutige Werte beinhaltet.
Fazit
Mit Facets können wir uns durch die Daten filtern, sie für die explorative Datenanalyse verwenden oder beim Data Cleaning zu bearbeitende Gruppen identifizieren und diese gesammelt korrigieren. Mit einem Grundverständnis von GREL können wir uns selbst Facets programmieren oder den Code der voreingestellten Facets anpassen. In Kombination mit regulären Ausdrücken können wir auf spezifischen Mustern basierende Facets erstellen.
Da die Facets nicht selbst benannt werden können, gibt es jedoch das Risiko, sich in seinen eigenen Filtern zu verlaufen.
Im nächsten Teil beschäftigen wir uns mit dem Import und Export von XML in OpenRefine.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.