Workshop - Daten mit OpenRefine Transponieren
 Folie - Daten mit OpenRefine Transponieren
Folie - Daten mit OpenRefine TransponierenOpenRefine kann Zeilen und Spalten tauschen. Diese Transposition kann sowohl auf dem kompletten Datensatz, als auch nur auf einer Auswahl an Spalten durchgeführt werden. In diesem Tutorial besprechen wir zwei Varianten des Transponierens.
Einführung
Transponieren in der OpenRefine Dokumentation.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
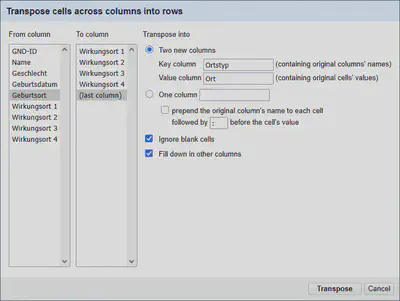
In der Praxis kommt es vor, dass wir Daten in Spalten organisiert bekommen, die wir eigentlich zeilenweise benötigen, oder umgekehrt. In der nächsten Tabelle ist ein Ausschnitt von Daten zu Politikern im Kabinett Kretschmann III gezeigt, mit dem wir im Laufe dieser Aufgabe arbeiten werden. Die Daten sind in Spalten gespeichert.
| GND-ID | Name | Geschlecht | Geburtsdatum | Geburtsort |
|---|---|---|---|---|
| 143926683 | Kretschmann, Winfried | Männlich | 1948-05-17 | Spaichingen |
| 122189930 | Hermann, Winfried | Männlich | 1952 | Rottenburg am Neckar |
| … | … | … | … | … |
In der nächsten Tabelle sind die gleichen Daten zeilenweise gespeichert. Mit der zusätzlichen “GND-ID” Spalte, die wir nicht mittransponiert haben, ergibt sich dadurch eine Record-Struktur, wie wir sie im letzten Teil des Workshops kennen gelernt und besprochen haben.
| GND-ID | Schlüssel | Wert |
|---|---|---|
| 143926683 | Name Geschlecht Geburtsdatum Geburtsort | Kretschmann, Winfried Männlich 1948-05-17 Spaichingen |
| 122189930 | Name Geschlecht Geburtsdatum Geburtsort | Hermann, Winfried Männlich 1952 Rottenburg am Neckar |
| … | Name Geschlecht Geburtsdatum Geburtsort | … |
Mit der Option Daten in OpenRefine zu transponieren, können wir Daten in den oben gezeigten Formaten ineinander umwandeln.
Vorbereitung: Projekt erstellen
Die folgende Datei in ein OpenRefine-Projekt laden.
Kretschmann III als CSV💾 Wir benötigen die folgende Datei (Rechtsklick und “Ziel speichern unter…”):
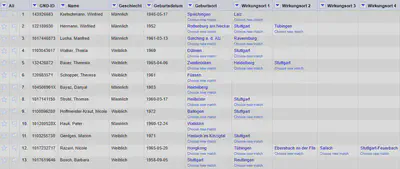
Die importierten Daten sind in Abbildung 1 gezeigt.
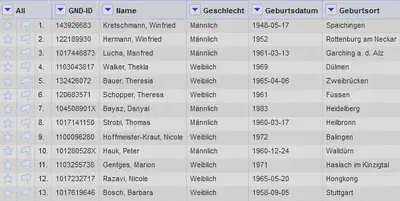
Aufgabe 1: Transponieren ohne Schlüsselspalte
Wir transponieren in dieser Aufgabe die in Abbildung 1 abgebildeten Daten in ein zeilenweises Datenformat. Dabei lassen wir die Spalte “GND-ID” stehen um anschließend eine Record-Struktur zu erzeugen.
Zum Transponieren gehen wir in den zugehörigen Dialog via “Name" "Transpose" "Transpose cells across columns into rows…” und wählen dort die zu transponierenden Spalten aus. Wie in Abbildung 2 geben wir als Zielformat an, dass wir die Daten in einer Spalte (One column) zusammengefasst bekommen möchten.
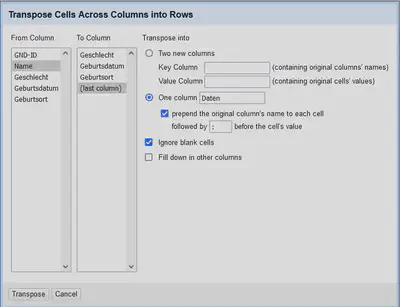
Das Ergebnis ist in Abbildung 3 gezeigt. Wir haben nun eine Record-Struktur mit der GND-ID als Identifikator und allen zugehörigen Daten in einem Record-Feld.

Der Schritt von einer zeilenweiser Speicherung zurück zu Spalten geht über
“Daten"
"Transpose"
"Transpose cells in rows into columns…”.
In dem Dialog geben wir 4 Zeilen zum Transponieren an.
Das Ergebnis ist in Abbildung 4 gezeigt.
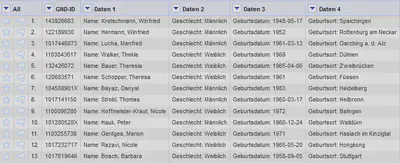
Hier sind auch schon zwei Nachteile beim Transponieren ohne Schlüssel zu sehen:
- Die Spalten müssen nachgearbeitet werden (Name ändern, Präfix entfernen).
- Die Daten müssen einheitlich sein, also gleiche Anzahl an Elementen und gleiche Sortierung, da die Umwandlung sonst “verrutscht”.
Aufgabe 2: Transponieren mit Schlüsselspalte
Wir machen die Änderungen rückgängig und stellen den in Abbildung 1 gezeigten Ursprungszustand des Projektes wieder her.
Diesmal transponieren wir die Daten in zwei Spalten, indem wir eine separate Schlüsselspalte erzeugen lassen. Dies funktioniert über den gleichen Dialog wie in Aufgabe 1 über “Name" "Transpose" "Transpose cells across columns into rows…”. Die Einstellungen sind in Abbildung 5 gezeigt.
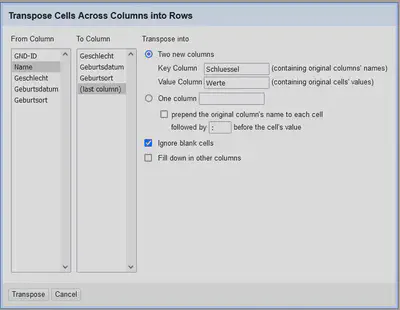
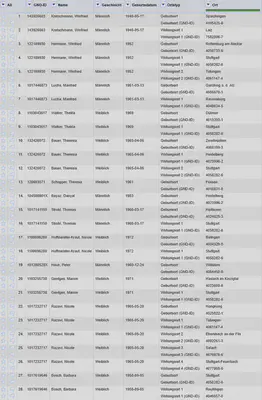
Das Ergebnis der Umwandlung ist in Abbildung 6 gezeigt. Wir haben eine Record-Struktur mit der GND-ID als Identifikator und allen zugehörigen Daten in einem Record-Feld.
Bevor wir von diesem Format zu einem Spaltenformat kommen, müssen wir zuerst die Records auflösen. Wir haben in diesem Datensatz nur eine Spalte (“GND-ID”) mit leeren Feldern, also genügt es diese über “GND-ID" "Edit cells" "Fill down” aufzufüllen.
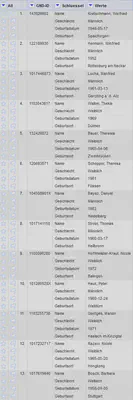
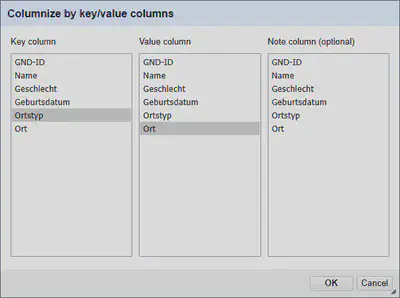
Anschließend können wir diesmal über “Schluessel" "Transpose" "Columnize by key/value columns…” mit den in Abbildung 7 gezeigten Einstellungen wieder zum Ursprungsformat zurückgelangen.
Diesmal benötigen wir anschließend keine Anpassungen oder im Vorfeld schon sortierte Daten. Lediglich die Schlüssel in der Spalte “Schluessel” sollten einheitlich geschrieben sein.
Aufgabe 3: Transponieren ausgewählter Spalten
Eine weitere praktische Anwendung des Transponierens liegt vor, wenn man mehrere Spalten von einem Typ hat, die man in einem Arbeitsgang zum Beispiel via Clustering vereinheitlichen oder mit einer Normdatenquelle abgleichen möchte. Für diese Aufgabe wurden exemplarisch die Daten des bisher verwendeten Datensatzes mit den jeweiligen Wirkorten der Politikerinnen und Politikern ergänzt. Das Ergebnis nach dem Import wird in Abbildung 8 gezeigt.
Kretschmann III als CSV💾 Wir benötigen die folgende Datei (Rechtsklick und “Ziel speichern unter…”):

Um alle Orte in der Tabelle in einem Arbeitsgang mit z.B. der GND abzugleichen, müssen wir die Daten der einzelnen Spalten in eine gemeinsame Spalte überführen. Dabei müssen wir uns merken, aus welcher Spalte die einzelnen Orte kommen, um sie nach dem Abgleich wieder zurück schreiben zu können.
Hierfür eignet sich ebenfalls das Transponieren. Die Voraussetzung dafür ist, dass die zu transponierenden Spalten alle direkt nacheinander gelistet sind. Dies lässt sich relativ komfortabel mit “ALL" "Edit columns" "Re-order / remove columns…” erledigen.
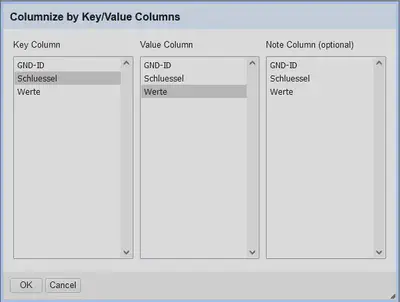
Anschließend werden nur die Ortsspalten über “Geburtsort" "Transpose" "Transpose cells across columns into rows…” zusammengeführt. Die Einstellungen sind in Abbildung 9 gezeigt.
Hierbei nicht vergessen, den Haken bei “Fill down in other columns” zu setzen. Das spart das spaltenweise Auffüllen der einzelnen Spalten vor der Rückumwandlung. Das Ergebnis nach der Umwandlung ist in Abbildung 10 gezeigt.
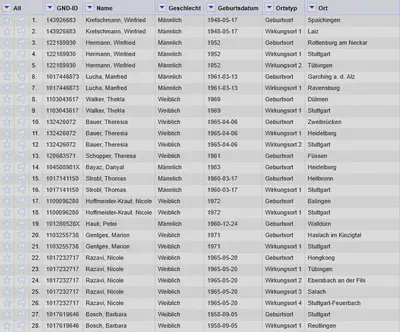
Nach dem Abgleich werden die Daten mit wie in Abbildung 11 gezeigt wieder in das Spaltenformat umgewandelt.
Das Ergebnis der Rückumwandlung ist in Abbildung 12 gezeigt. Bei Bedarf kann man die Ortsspalten jetzt wieder einsortieren und/oder für jede Ortsspalte eine GND-ID Spalte hinzufügen mit “Ortsspalte" "Reconcile" "Add entity identifiers column…”.
Automatischer Fill-down
Sollte man beim Umwandeln in das Zeilenformat vergessen haben, den Haken bei “Fill down in other columns” zu setzen, dann kann man das noch spaltenweise mit “Spaltenname" "Edit cells" "Fill down” nachholen.
Hat man sehr viele Spalten, so kann man stattdessen via “ALL" "Transform…” den folgenden GREL Ausdruck verwenden.
if(isBlank(value), row.record.cells[columnName][0].value, value)
Dabei ist darauf zu achten, dass man die ID-Spalte entweder auslässt und separat auffüllt, oder die ID-Spalte bei der Massenbearbeitung via “Drag&Drop” ans Ende verschiebt. Ansonsten ändert sich die “Record”-Struktur, bevor alle Spalten befüllt wurden und der GREL-Ausdruck funktioniert nicht mehr.
Alternative für GND-ID Spalten
Hat man sehr viele Ortsspalten, dann lässt sich die Erzeugung der GND-ID-Spalten auch etwas automatisieren.
Nachdem man die Daten mit der GND abgeglichen hat (also bevor man die Zeilen wieder in Spalten überführt), ergänzt man die GND-Nummer im Namen des Ortes über “Ort" "Edit cells" "Transform…” und dem folgenden GREL Ausdruck.
value + "||" + cell.recon.match.id
Anschließend werden die Werte via
“Ort"
"Edit cells"
"Split multi-valued cells…”
und den Trennzeichen || in mehrere Zeilen aufgeteilt.
Der zukünftige Spaltenname wird ergänzt via “Ortstyp" "Edit cells" "Transform…” und dem folgenden GREL Ausdruck.
if(isBlank(value), row.record.cells[columnName][0].value + " (GND-ID)", value)
Das Ergebnis sieht dann wie in Abbildung 13 aus. Dort müssen jetzt noch die restlichen Spalten vor der Umwandlung in das auf Spalten basierte Format zum Beispiel mit “Fill down” aufgefüllt werden
Fazit
Transponieren in OpenRefine hat noch weitere Features, wie zum Beispiel die Berücksichtigung von extra Spalten, mehreren Werten und separaten Spalten für Notizen. Dabei ist OpenRefine gerade beim Unwandeln von zeilenweisen Daten in spaltenweise sehr sensibel gegenüber der Sortierung der Werte in der Schlüsselspalte und ggf. weiteren Spalten, die nicht mit umgewandelt werden sollen.
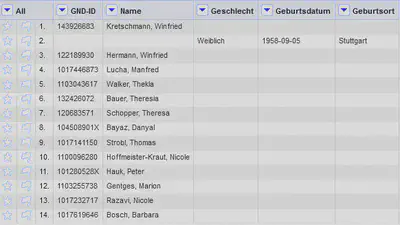
Ein typischer Fehler ist zum Beispiel die Umwandlung von “Records” mit “Columnize by key/value columns” ohne die “Records” vorher mit “Fill down” aufzulösen. Das führt dazu, dass “Leer” als eigener Wert berücksichtigt wird und OpenRefine die Daten dadurch wie in Abbildung 8 sehr unerwartet sortiert.
Im nächsten Teil ergänzen wir mit OpenRefine ein Projekt mit Daten aus anderen Projekten.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.