Workshop - Arbeiten mit Records in OpenRefine
 Folie - Arbeiten mit Records in OpenRefine
Folie - Arbeiten mit Records in OpenRefineOpenRefine kann im Zeilen- oder Records-Modus arbeiten. In diesem Tutorial besprechen wir, wie wir Records aus auf Zeilen basierten Datensätzen erstellen, wie wir mit Records arbeiten können und wie wir Records wieder in auf Zeilen basierte Datensätze umwandeln.
Einführung
Records in der OpenRefine Dokumentation.
Records mit GREL in der OpenRefine Dokumentation.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
Um in OpenRefine zwischen dem Zeilen- und dem Record-Modus zu wechseln, gibt es in der oberen Bedienleiste, die in Abbildung 1 gezeigten Schaltflächen.

Diese Schaltflächen ändern, wie OpenRefine aufeinanderfolgende Zeilen anzeigt, filtert, und bearbeitet. Betrachten wir den folgenden Ausschnitt aus dem Kabinett Kretschmann III, mit dem wir auch die folgenden Praxisaufgaben durchführen werden.
| All | Name | Beruf |
|---|---|---|
| 1. | Kretschmann, Winfried | Abgeordneter |
| 2. | Lehrer | |
| 3. | Politiker | |
| 4. | Regierungschef | |
| 5. | Walker, Thekla | Pädagogin |
| 6. | Politikerin | |
| 7. | Weibliche Abgeordnete |
Diese Tabelle zeigt, wie OpenRefine im Zeilenmodus mit den Daten umgeht. Jede Zeile steht für sich und hat auch eine eigene Zeilennummer. Wird in diesem Modus in der Spalte “Beruf” nach dem Wert “Politik” gefiltert, dann werden in diesem Modus nur die Zeilen 3. und 6. angezeigt. Man weiß also nicht, zu welcher Person dieser Wert gehört.
Im Record-Modus betrachtet OpenRefine die 1. Spalte, nimmt die erste Zelle mit einem Wert (z.B. Zeile 1) und fasst sie mit den folgenden Zeilen mit einer leeren Zelle in der 1. Spalte (Zeilen 2 - 4) wie in der nächsten Tabelle gezeigt zu einem Record zusammen.
| All | Name | Beruf |
|---|---|---|
| 1. | Kretschmann, Winfried | Abgeordneter Lehrer Politiker Regierungschef |
| 2. | Walker, Thekla | Pädagogin Politikerin Weibliche Abgeordnete |
Entsprechend wird auch die Anzeige geändert und zum Beispiel nicht mehr die Zeilen durchnummeriert, sondern die Records. Das ermöglicht es mit OpenRefine baumartige Strukturen zu importieren, zu verarbeiten und zu exportieren.
In den folgenden praktischen Übungen werden wir das Arbeiten mit Records praktisch ausprobieren und dabei auch einige für Records spezifische GREL Ausdrücke kennen lernen.
Vorbereitung: Projekt erstellen
Die folgende Datei in ein OpenRefine-Projekt laden.
Kretschmann III als CSV💾 Wir benötigen die folgende Datei (Rechtsklick und “Ziel speichern unter…”):
Aufgabe 1: Records aus wiederholenden Zeilen erstellen
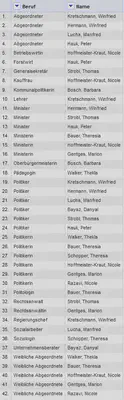
Wir starten wie in Abbildung 2 gezeigt mit den Berufen der Mitglieder im Kabinett Kretschmann III (abgerufen am 03.12.2021 aus der GND). Unser Ziel ist es, einen Überblick über alle Berufe eines Mitgliedes des Kabinetts zu erhalten.
Dafür verschieben wir die Spalte “Name” via “Name" "Edit column" "Move column to beginning” ganz nach links. Anschließend sortieren wir die Spalte “Name” alphabetisch via “Name" "Sort…” und fixieren diese Sortierung wie in Abbildung 3 zu sehen via “Sort" "Reorder rows permanently”.

Danach entfernen wir die Mehrfachnennung der Namen via “Name" "Edit cells" "Blank down”. Das Ergebnis sieht dann wie in Abbildung 4 aus.
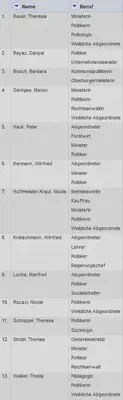
Typische Anwenderfehler bei “Blank down”:
- Vergessen auf den “Zeilenmodus” (rows) umzuschalten.
- Inhalte sind nicht alle vom Typ Text.
Aufgabe 2: Arbeiten mit Records
Die Record Struktur hilft uns beim Verarbeiten baumartiger Strukturen, wie es beim Lesen und Schreiben von XML vorkommt. Hier ein paar hilfreiche Funktionen zum Arbeiten mit Records, deren Ergebnisse in Abbildung 5 gezeigt sind.
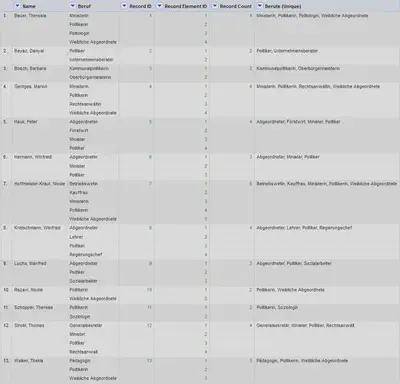
Um Aktionen auf Records anzuwenden, wechseln wir in den Records-Modus.
Records filtern
Das Verwenden von Filtermöglichkeiten mit Records kann manchmal etwas verwirrend sein. Um dies zu demonstrieren verwenden wir eine Kombination aus Textfacet und Textfilter auf der Spalte Beruf via “Beruf" "Facet" "Text facet” und “Beruf" "Textfilter”.
In dem Textfilter suchen wir dann nach dem Begriff “Recht”.
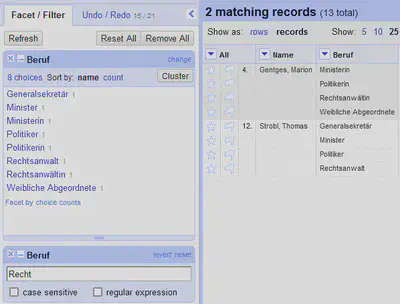
Wie in Abbildung 6 zu sehen, werden im Record-Modus bei der Verwendung eines Textfilters alle Records angezeigt, die eine Zeile haben, auf die der Textfilter passt. In unserem Fall sind das Minister Strobl und Ministerin Gentges, die beide in der GND Rechtsanwältin bzw. Rechtsanwalt als Berufsangabe haben.
Das ist auch nachvollziehbar und sinnvoll. Gleichzeitig bedeutet es, dass das Textfacet nicht auf Werte reduziert wird, die den Begriff “Recht” im Namen haben (Rechtsanwalt und Rechtsanwältin), sondern alle Werte angezeigt werden, die in den beiden gefilterten Records vorkommen. Das ist ebenfalls nachvollziehbar und sinnvoll, überrascht aber manchmal, da man im Kopf noch/schon im Zeilenmodus denkt.
Daher ist gerade beim Filtern mit Records im Hinterkopf zu behalten, dass manchmal zwischen dem Zeilen- und Record-Modus hin- und hergewechselt werden sollte.
Records durchnummerieren
Wir erstellen eine neue Spalte “Record ID” via “Beruf" "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
row.record.index + 1
Anschließend verwenden wir “Record ID" "Edit cells" "Blank down” um die überzähligen IDs zu entfernen.
Elemente in Records durchnummerieren
Wir erstellen eine neue Spalte “Record Element ID” via “Record ID" "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
1 + row.index - row.record.fromRowIndex
Elemente in Records zählen
Wir erstellen eine neue Spalte “Record Count” via “Record Element ID" "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
if(value==1, row.record.rowCount, null)
Hier sparen wir uns das anschließende “Blank down”, da wir über eine if-Anweisung die Anzahl nur in Zeilen mit der Record Element ID 1 geschrieben haben.
Elemente Sortieren/Doppelungen entfernen
Wir transformieren die Spalte “Beruf” via “Beruf" "Edit cells" "Transform…” und verwenden einen der folgenden GREL Ausdrücke.
Doppelungen entfernen:
row.record.cells["Beruf"].value.uniques().join(", ")
Nur sortieren:
row.record.cells["Beruf"].value.sort().join(", ")
Doppelungen entfernen und sortieren:
row.record.cells["Beruf"].value.uniques().sort().join(", ")
Wie wir daraus wieder Records bekommen, ist in “04 Records aus Feldern mit mehreren Werten erstellen” beschrieben.
Aufgabe 3: Records in Felder mit mehreren Werten auflösen
Da nicht alle Zielprogramme mit einer Record-Struktur klarkommen, müssen diese manchmal auch wieder umgewandelt werden. Eine Möglichkeit sind so genannte “Multi-Value-Fields”, oder Felder mit mehreren Werten. In unserem Beispiel könnte das eine mit Komma separierte Liste aller Berufe sein.
Dafür verwenden wir
“Beruf"
"Edit cells"
"Join multi-valued cells…”
und wählen als Trennzeichen eine Zeichenfolge aus Komma und Leerzeichen ,.
Das Ergebnis der Operation ist in Abbildung 7 gezeigt.
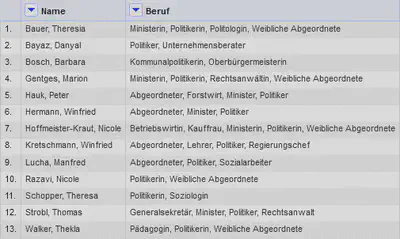
Möchte man die Werte in mehrere Spalten aufteilen, so kann dafür “Beruf" "Edit column" "Split into several columns…” verwendet werden. Das Ergebnis der Operation ist in Abbildung 8 gezeigt.

Aufgabe 4: Records aus Feldern mit mehreren Werten erstellen
Im FDMLab kommt es öfter vor, dass wir Datensätze mit “Multi-Value-Fields”, wie in Abbildung 7, oder die Daten aufgeteilt auf mehrere Spalten, wie in Abbildung 8 bekommen.
Diese wandeln wir dann in Records um, um zum Beispiel die Schreibweise via Clustering zu vereinheitlichen, oder ein gemeinsames Reconciling der Daten durchzuführen.
Dafür machen wir die in “03 Records in Felder mit mehreren Werten auflösen” durchgeführten Änderungen wieder rückgängig, ohne die History-Funktion zu verwenden.
Zuerst fügen wir die Spalten wieder via “Beruf 1" "Edit column" "Join columns…” zusammen. Die Einstellungen sind in Abbildung 9 gezeigt.
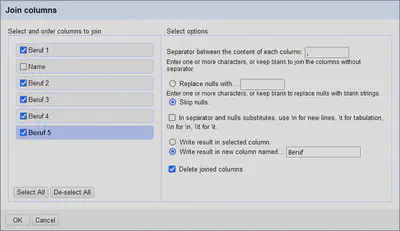
Anschließend erstellen wir die Record-Struktur via
“Beruf"
"Edit cells"
"Split multi-valued cells…”
und wählen als Trennzeichen die gleiche Trennsequenz, wie beim Zusammenfügen der Spalten in Abbildung 9.
In unserem Fall also ,.
Wir sind nun wieder bei der Record-Struktur wie in Abbildung 4 angekommen.
Aufgabe 5: Records in wiederholende Zeilen auflösen
Manchmal wollen wir von der Record-Struktur auch zu sich wiederholenden Werten in Zeilen wechseln, wie wir es ganz zu Beginn dieses Tutorials in Abbildung 2 gesehen haben.
Wir gehen davon aus, dass wir eine Record-Struktur wie in Abbildung 4 haben. Dort nutzen wir dann das Gegenstück zu “Blank down” via “Name" "Edit cells" "Fill down” .
Um zum “Original” in Abbildung 2 zu kommen, müssten wir die Spalte “Beruf” noch alphabetisch sortieren und ganz nach links verschieben.
Fazit
Mit Records lassen sich interessante Datentransformationen bewerkstelligen. Bei der Aufbereitung von Findbüchern mit OpenRefine haben wir damit zum Beispiel die Inhalte von zweispaltigen Seitenlayouts in einzelne Zeilen umgewandelt.
Zu Beginn ist das Konzept potentiell noch neu und ungewohnt, wer sich jedoch tiefer damit beschäftigt, kann damit Probleme lösen, die man sonst an Programmiersprachen wie Clojure oder Jython in OpenRefine delegieren würde.
Im nächsten Teil behandeln wir das Konzept des Transponierens mit dem wir in OpenRefine ähnliche Probleme behandeln können.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.