Workshop - Daten mit OpenRefine clustern
 Folie - Daten mit OpenRefine clustern
Folie - Daten mit OpenRefine clusternWir verwenden verschiedene Clustering Methoden in OpenRefine, um Schreibweisen zu vereinheitlichen.
Clustering in der OpenRefine Dokumentation.
Clustering im OpenRefine Wiki.
Dieser Workshop wurde zuletzt getestet mit OpenRefine Version 3.9.3.
Hintergrund
OpenRefine implementiert unterschiedliche Methoden, um Cluster in Mengen von Werten zu finden. Dies hilft uns beim Vereinheitlichen von Werten, finden von Tippfehlern, usw.
Im folgenden Diagramm ist dargestellt, wie alle Vorkommen von “Michael Müller” in einer Liste von Namen zusammengefasst werden können. Ein einfaches Sortieren nach Namen genügt hier nicht, da “Michael Müller” unterschiedlich geschrieben wurde. Hier ist eine Deduplizierung erforderlich, wofür in OpenRefine Clustering eingesetzt werden kann.
Hier eine Übersicht über die verschiedenen Arten von Cluster-Verfahren und welche Probleme sie lösen. Die Zusammenfassung basiert auf Clustering In Depth aus dem OpenRefine Wiki und aus unseren Erfahrungen beim Clustering von Namen mit OpenRefine.
Fingerprint Verfahren (schnell)
| Name | Beschreibung | Beispiel | Kommentar |
|---|---|---|---|
| Fingerprinting | Normalisiert und Sortiert auf Wortebene. Entfernt Satzzeichen! |
| Probleme mit kleinen Abweichungen. |
| N-Gram Fingerprinting | Normalisiert und sortiert auf Buchstabenebene |
| Schnell und hilft z.B. bei Buchstabendrehern. |
Die Fingerprinting Methoden sind sehr schnell und helfen bei typischen Problemen wie Wortreihenfolgen, unterschiedlicher Verwendung von Sonderzeichen oder Satzzeichen. OpenRefine bietet hier ein Verfahren auf Wortebene und eines auf Buchstabenebene an.
Hierbei ist zu beachten, dass schon kleine Abweichungen (ein zusätzliches/anders geschriebenes Wort) dazu führen, dass ein Text aus einem Cluster ausgeschlossen wird.
Phonetische Verfahren
| Name | Sprache | Beispiel |
|---|---|---|
| Cologne-phonetic | Deutsch | Meier, Maier, Mayer, Mayr. |
| Metaphone3 | Englisch | Reuben Gevorkiantz und Ruben Gevorkyants. |
| Daitsch-Moktoff | Slawisch und Jiddisch | Moskowitz und Moskovitz. |
| Beider-Morse | Slawisch und Jiddisch | Weniger Falsch-Positive als Daitsch-Moktoff. |
Die phonetischen Verfahren berücksichtigen, dass manche Buchstaben in der gesprochenen Sprache die gleichen Laute erzeugen. Das ist gerade für Namen in historischen Dokumenten sinnvoll, da diese häufig nach Hörverständnis geschrieben werden.
OpenRefine hat Implementierungen für die deutsche Sprache in Form von Cologne Phonetic, für die englische Sprache in Form von Metaphone, und für slawische Sprachen und Jiddisch Daitsch-Moktoff und Beider-Morse.
Nearest-Neighbor-Verfahren (langsam)
| Name | Beschreibung | Beispiel | Kommentar |
|---|---|---|---|
| Levensthein | $d(A, B) = repl + ins + del$ |
|
|
| Prediction by Partial Matching | $d(A, B) = \frac{compress(A, B) + compress(B, A)}{compress(A, A) + compress(B, B)}$ |
|
|
Die Levensthein Distanz berechnet die Ähnlichkeit zwischen zwei Texten, indem sie die notwendigen Änderungsoperationen (Ersetzungen, Einfügungen, Löschungen) zählt, die notwendig sind um zwei Texte ineinander zu überführen. Die Berechnung ist jedoch recht aufwendig. Dafür ist die Levensthein Methode hilfreich um Tippfehler oder OCR-Fehler zu identifizieren.
Bei Prediction by Partial Matching werden Kompressionsverfahren verwendet. Die Annahme dabei ist, dass Texte mit ähnlichen Inhalten (strukturell, nicht semantisch!) komprimiert ähnlich aussehen. Das ist gerade bei längeren Texten hilfreich, bei kurzen Texten (einzelne Worte) ist das Verfahren nicht so erfolgreich.
Probleme beim Clustering
Auch wenn man mit den Clustering Methoden schnell zu sinnvollen Ergebnissen kommt, gibt es einige Bereiche, für die es in OpenRefine (noch) keine Lösungen gibt, bzw. spezialisierte Clustering Methoden notwendig wären. Hier eine unvollständige Liste von separat zu behandelnden Problemen mit Beispielen:
- Abkürzungen: w, weibl., weiblich
- Synonyme: ledig, single, alleinstehend, frei, unverheiratet
- Bestimmte OCR-Fehler: Fleinrich und Heinrich
- Fehlende Zweitnamen: Speckmann, Johann Stefan
- Fehlende Namensbestandteile: Albrecht (von Lauterburg) Johann Konrad
- Alternative Schreibweisen: Greck, Leo und Greck (Gregk), Leo
Aufgabe 1: Clustering mit “fingerprint” Methoden
Die Spalte “Todesdatum (beschreibend)” sieht auf den ersten Blick recht aufgeräumt aus.
Wir testen auf dieser Spalte die Cluster-Methoden “fingerprint” und “ngram-fingerprint”. Den Dialog für das Clustering öffnen wir entweder über die Bedienfläche “Cluster” im “Text Facet” der Spalte, oder über das Spaltenmenü “Todesdatum (beschreibend)“ "Edit cells" "Cluster and edit…”.
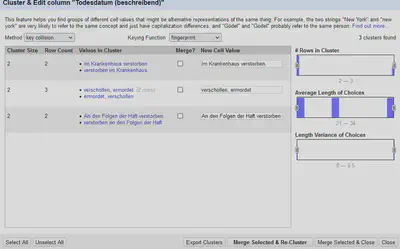
Wie in Abbildung 1 zu sehen, wird automatisch die “fingerprint” Methode ausgeführt, die auch gleich drei mögliche Cluster findet. Diese unterscheiden sich lediglich in der Reihenfolge der Satzstellung sowie Groß- und Kleinschreibung.
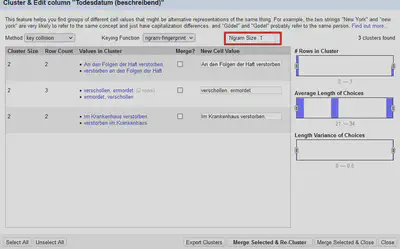
Wir führen diese Cluster noch nicht zusammen, sondern schauen uns noch die Ergebnisse der “NGram-Fingerprint” Methode an. Diese findet in den Standardeinstellungen hier keine Cluster, sondern erst, wenn wir, wie in Abbildung 2 markiert, die Größe auf 1 reduzieren.
Aufgabe 2: Clustering mit phonetischen und “Nearest-Neighbor”-Methoden
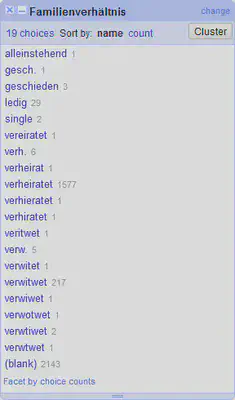
Die Spalte “Familienverhältnis” beinhaltet unterschiedliche Abkürzungen und Tippfehler. Testen Sie verschiedene phonetische und “Nearest-Neighbor”-Methoden zum Clustern aus.
Aufgabe 3: Clustern?
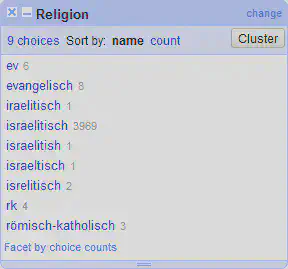
Auch in der Spalte “Religion” haben sich unterschiedliche Abkürzungen und Tippfehler eingeschlichen. Lohnt sich hier ein Clustering, oder besser eine Kombination aus “Text Facet” und Textfilter?
Fazit
Die in OpenRefine implementierten Clusteringverfahren sind mächtig und komfortabel integriert. Auch wenn man ohne Hintergrundwissen über die einzelnen Clusteringverfahren zu einem brauchbaren Ergebnis kommt, ist es sinnvoll sich im Vorfeld einen passenden Workflow zurechtzulegen. Je nach Datenmenge wartet man sonst unnötig lange auf das Ergebnis eines aufwendiger zu berechnenden Nearest-Neighbor-Verfahrens.
Hier gibt es im GLAM-Bereich auch durchaus noch Potential weitere Clusteringverfahren zu implementieren. Zum Beispiel zur Korrektur von OCR-Fehlern, Berücksichtigung von Synonymen, oder Worteinbettungen wie Bag-of-Words Modelle und Word2Vec.
Im nächsten Teil beschäftigen wir uns mit dem Abgleich von Daten in OpenRefine mit der Gemeinsamen Normdatei (GND) über das lobid API.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.