Gemeinsam an OpenRefine-Projekten arbeiten
 Bild von congerdesign auf Pixabay.
Bild von congerdesign auf Pixabay.Im FDMLab testeten wir verschiedene Möglichkeiten mit OpenRefine gemeinsam an Projekten zu arbeiten. Dieser Artikel fasst unsere Erfahrungen beim kollaborativen Arbeiten mit OpenRefine 3.5.0 zusammen.
Wir hatten in Fünf Dinge, die wir an OpenRefine mögen schon darüber berichtet, dass uns die Architektur von OpenRefine gefällt, da sie es ermöglicht OpenRefine sowohl auf einem Client (Laptop, Rechner), als auch auf einem Server laufen zu lassen. Die Bedienung erfolgt anschließend über den Browser.
Da läge es nahe, dass OpenRefine auch eine Benutzerverwaltung und eine Möglichkeit zum Kollaborativen Arbeiten an Projekten anbietet. Dafür gab es Pläne ein Broker Protokoll für OpenRefine einzuführen, die bisher aber weder umgesetzt noch eingeplant wurden.
In der Dokumentation von OpenRefine wird folgendes Vorgehen empfohlen:
Die beste Art, mit einer anderen Person zusammenzuarbeiten, ist, Projekte zu exportieren und zu importieren, wobei alle Änderungen gespeichert werden, so dass Sie an der Stelle weiterarbeiten können, wo die andere Person aufgehört hat.
Übersetzt von Starting a project: Import a project, aufgerufen am 01.12.2021.
Konkret bedeutet das, dass bei einer Kooperation von Alice, Bob und Charly zwar alle an dem gleichen Projekt arbeiten können, jedoch nicht gleichzeitig. Nachdem Alice das Projekt an Bob übergeben hat, arbeitet Bob daran. Nachdem Bob fertig ist, übergibt er das Projekt an Alice zurück, die es an Charly übergibt. Nachdem Charly fertig ist, übergibt er das Projekt an Alice zurück, die dann erst daran weiterarbeiten kann. Das war für uns im FDMLab ein eher unbefriedigender Zustand, weshalb wir zu einer anderen Strategie gewechselt haben.
Wir haben angefangen Teile eines Projektes in OpenRefine auszulagern und nach erfolgreicher Bearbeitung wieder in das Originalprojekt einzupflegen. So kann in unserem Beispiel Alice weiter an dem Projekt arbeiten, während Bob und Charly sie durch die Bearbeitung einzelner Teile unterstützen. Diese Teile werden anschließend von Alice wieder in das Originalprojekt eingepflegt. Wie das funktioniert besprechen wir in den folgenden Unterpunkten.
Zeilenweise zusammenführen
Manchmal ist es möglich, ein Projekt zeilenweise aufzuteilen. Also dass Alice die ersten 100 Zeilen, Bob die nächsten 100 und Charly die letzten 75 Zeilen bearbeitet.
Die Ergebnisse können nach der Bearbeitung als CSV-Dateien exportiert und daraus anschließend ein neues OpenRefine-Projekt erstellt werden.

Wie in Abbildung 1 gezeigt, kann OpenRefine ein Projekt aus mehreren Dateien erstellen. Das kann auch ein Dateiarchiv sein, dessen Dateien in ein neues Projekt importiert werden.
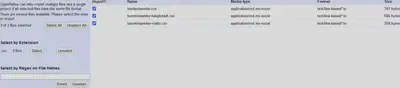
Bevor das Projekt konfiguriert wird, gibt es wie in Abbildung 2 gezeigt, die Möglichkeit einzelne Dateien aus- oder abzuwählen. Im Idealfall haben die einzelnen Dateien schon die gleichen Spaltenüberschriften in der richtigen Reihenfolge. Ansonsten bietet OpenRefine mit der Möglichkeit Spalten zu verbinden und Spalten zu verschieben die Möglichkeit das nachträglich zu bereinigen.
Spaltenweise zusammenführen
Ein häufiger Anwendungsfall im FDMLab ist, dass das Aufräumen und Transformieren der Daten von einer Person erledigt wird, die zum Beispiel beim Reconciling oder dem Abgleich mit weiteren Datenquellen von weiteren Personen unterstützt wird. Dafür werden einzelne Spalten als CSV (oder Excel) exportiert, von der unterstützenden Person bearbeitet und die Ergebnisse dann wieder in das Originalprojekt übernommen.
Ein anderer Fall kann sein, dass es schon einen anderen Datensatz gibt, dessen Daten komplett oder teilweise übernommen werden sollen. Das haben wir in Findbuchdaten mit OpenRefine wiederverwenden teilweise besprochen.
Beispiel
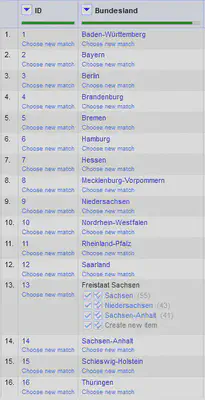
In unserem fiktiven Beispiel arbeitet Alice mit einem Datensatz der 16 Bundesländer, wie er in Abbildung 3 gezeigt ist. Diesen gibt sie an Bob und Charly weiter.

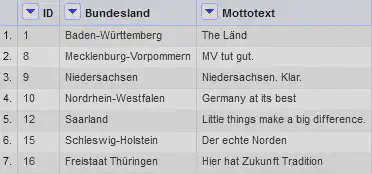
Bob unterstützt Alice, indem er für die 16 Bundesländer das “Motto” recherchiert, er kann jedoch nicht für alle Bundesländer ein Motto finden und liefert den in Abbildung 4 gezeigten Datensatz zurück. 1
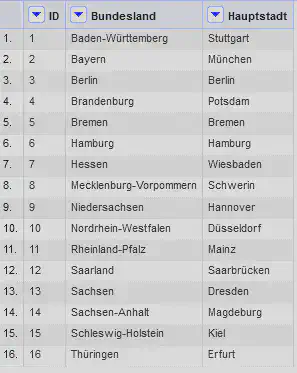
Charly hat die Aufgabe die Hauptstädte der einzelnen Bundesländer zu recherchieren, und liefert den in Abbildung 5 gezeigten Datensatz zurück. Dabei wurden jedoch die Namen der Bundesländer teilweise geändert, also zum Beispiel der Begriff “Freistaat” aus dem Namen wegoptimiert.
Datensätze herunterladen
Die drei beschriebenen Datensätze können hier heruntergeladen werden, um die vorgestellten Methoden zum Zusammenführen von Daten beim gemeinsamen Arbeiten in OpenRefine selbst auszuprobieren
Bundesländer als CSVBundesländer Motto als CSVBundesländer Hauptstädte als CSV💾 Wir benötigen drei Dateien (Rechtsklick und “Ziel speichern unter…”):
ID Spalte erstellen
Wir werden die Daten auf drei Arten abgleichen:
- Via einer dedizierten ID-Spalte
- Mit einer improvisierten ID-Spalte (Name des Bundeslandes)
- Via Reconciling
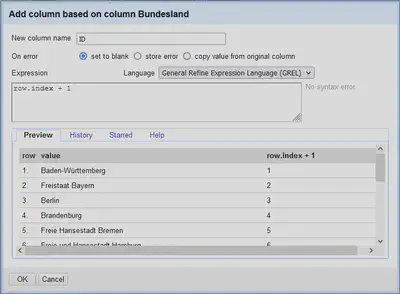
Idealerweise haben alle Datensätze eine einheitliche ID-Spalte zum Abgleichen. Diese lässt sich in OpenRefine über “Spaltenmenü" "Edit column" "Add column based on this column…” mit dem folgenden GREL Ausdruck anlegen:
row.index + 1
Wie in Abbildung 6 gezeigt, wird so eine ID-Spalte erzeugt, deren Nummerierung analog zur Nummerierung der Zeilen in OpenRefine verläuft.
Alternativ lassen sich manchmal auch ID-Spalten improvisieren, indem zum Beispiel bei Personen die Namen und Vornamen in eine ID-Spalte übernommen werden.
Zusammenführen mit cross()
Alice hat von Bob und Charly zwei CSV-Dateien bekommen, die sie in ihr OpenRefine-Projekt übernehmen möchte. Eine Möglichkeit, das innerhalb von OpenRefine zu erledigen, ist die Funktion cross().
Im OpenRefine-Wiki gibt es einige Beispiele zur Anwendung von cross(). Außerdem gibt es eine OpenRefine-Erweiterung für cross() um die Funktion über Dialoge in der Oberfläche von OpenRefine zu verwenden.
Wir verwenden die Funktion cross() ohne Erweiterung. Dafür erstellen wir für die drei Datensätze jeweils ein Projekt.
- Projekt “Bundesländer” aus
bundeslaender.csv - Projekt “Bundesländer Motto” aus
bundeslaender-motto.csv - Projekt “Bundesländer Hauptstadt” aus
bundeslaender-hauptstadt.csv
cross() damit klarkommt!Zusammenführen via ID
Idealerweise haben wir eine eindeutige ID-Spalte, um die Projekte miteinander abzugleichen.
Mit cross() können wir über die ID-Spalte Daten aus einem anderen OpenRefine-Projekt nachladen.
Das funktioniert aber nur, wenn die IDs eindeutig sind.
Nachladen des Mottos
Zum Nachladen des Mottos der Bundesländer gehen wir im “Bundesländer”-Projekt über das Spaltenmenü “ID" "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
cell.cross("Bundesländer Motto", "ID").cells["Mottotext"].value[0]
Dabei ist “Bundesländer Motto” der Name des Projektes aus dem wir die Daten holen wollen, und “ID” die ID-Spalte im Projekt “Bundesländer Motto”.
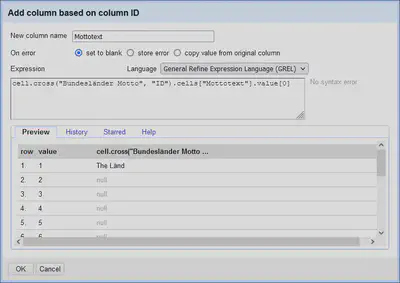
Wie in Abbildung 7 gezeigt, werden die Daten (also der Mottotext) aus dem anderen Projekt nachgeladen. Es haben nicht alle Bundesländer einen Mottotext hinterlegt, was den Abgleich nicht weiter stört.
Nachladen der Hauptstadt
Zum Nachladen der Hauptstadt der Bundesländer gehen wir im “Bundesländer”-Projekt über das Spaltenmenü “ID" "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
cell.cross("Bundesländer Hauptstadt", "ID").cells["Hauptstadt"].value[0]
Dabei ist “Bundesländer Hauptstadt” der Name des Projektes aus dem wir die Daten holen wollen, und “ID” die ID-Spalte im Projekt “Bundesländer Hauptstadt”.
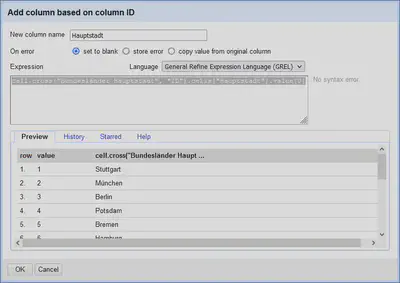
Wie in Abbildung 8 gezeigt, werden die Daten (hier die Hauptstadt) aus dem anderen Projekt nachgeladen. Es haben alle Bundesländer eine Hauptstadt, so dass der Abgleich hier für jeden Eintrag ein Ergebnis produziert.
Außerdem ist zu erwähnen, dass sich OpenRefine hier auch nicht daran stört, dass die ID-Spalte bei uns im Projekt “Bundesländer” als Zahl, im Projekt “Bundesländer Motto” jedoch als Typ Text gespeichert ist.
Zusammenführen via Werte
Es ist nicht immer eine eindeutige ID-Spalte vorhanden. Das kommt zum Beispiel vor, wenn die Daten aus verschiedenen Projekten stammen.
Man kann auch ID-Spalten improvisieren, was aber nicht immer zum gewünschten Ergebnis führt.
Wir werden den Abgleich mit cross() diesmal über die Spalte “Bundesland” durchführen.
Nachladen des Mottos
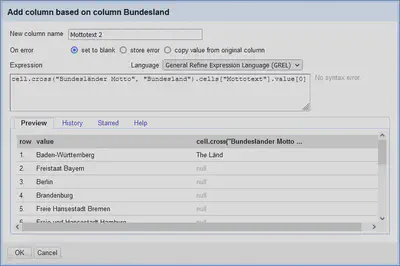
Zum Nachladen des Mottos der Bundesländer gehen wir im “Bundesländer”-Projekt diesmal über das Spaltenmenü “Bundesland“ "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
cell.cross("Bundesländer Motto", "Bundesland").cells["Mottotext"].value[0]
Wie in Abbildung 9 zu sehen ist, hat der Abgleich zwischen diesen beiden Projekten kein Problem, da die Bundesländer hier einheitlich geschrieben sind.
Nachladen der Hauptstadt
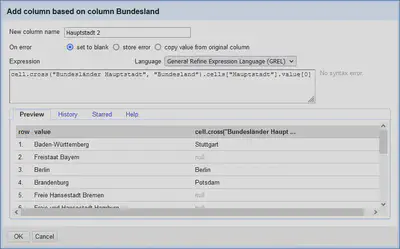
Zum Nachladen der Hauptstädte der Bundesländer gehen wir im “Bundesländer”-Projekt diesmal über das Spaltenmenü “Bundesland“ "Edit column" "Add column based on this column…” und verwenden den folgenden GREL Ausdruck.
cell.cross("Bundesländer Hauptstadt", "Bundesland").cells["Hauptstadt"].value[0]
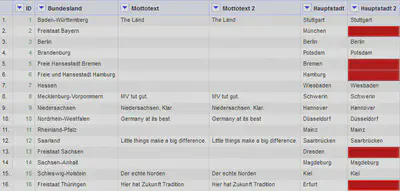
Wie in Abbildung 10 zu sehen ist, hat der Abgleich hier Probleme, da die Bundesländer teilweise unterschiedlich geschrieben sind. Es fehlen Ergänzungen wie “Freistaat”. Daher können die Daten für diese Bundesländer nicht nachgeladen werden.
Ergebnis
Der Abgleich mit cross() innerhalb von OpenRefine funktioniert recht einfach, solange es eine Spalte mit eindeutigen Werten gibt.
Der Abgleich stört sich auch nicht an Sonderzeichen, Leerzeichen oder fehlenden Werten.
Problematisch wird es, wenn die Werte der Spalten, die abgeglichen werden, nicht komplett übereinstimmen. Diese sind in Abbildung 11 farblich hervorgehoben. In solchen Fällen empfiehlt sich das im nächsten Abschnitt besprochene lokale Reconciling.
Zusammenführen mit lokalem Reconciling
Wir hatten in Fünf Dinge, die wir an OpenRefine mögen schon die Architektur von OpenRefine gelobt, da diese so gestaltet ist, dass OpenRefine auch mit anderen APIs kommunizieren kann. Besonders unterstützt ist dabei das Reconciliation Service API Protokoll. Damit können Daten in einem OpenRefine-Projekt nicht nur gegen Wikidata oder die GND abgeglichen werden, sondern mit Werkzeugen wie csv-reconcile auch mit lokalen CSV-Dateien.
Für die Verwendung von csv-reconcile benötigt man Python auf seinem System. Ist Python vorhanden, dann kann csv-reconcile einfach via Shell (PowerShell, Git Bash, …) installiert werden. Wir erstellen dafür erst eine virtuelle Umgebung in unserem Arbeitsordner, um csv-reconcile ausschließlich dort zu installieren.
Der Arbeitsordner ist der Ordner, in dem wir unsere CSV-Dateien liegen haben, mit denen wir hier arbeiten.
Die virtuelle Umgebung für Python ermöglicht es uns, Python Bibliotheken nur für dieses Projekt zu installieren, so dass sie nicht mit Bibliotheken oder Python Versionen in anderen Projekten in Konflikt kommen.
> python -m venv venv # virtuelle Umgebung erstellen
> .\venv\Scripts\activate # virtuelle Umgebung aktivieren (Windows!)
(venv) > pip install csv-reconcile # csv-reconcile in virtuelle Umgebung installieren
Da csv-reconcile in Version 0.3.0 den Vorschaudienst optional anbietet und keine automatische Erkennung von Encoding und Trennzeichen in CSV-Dateien hat, erstellen wir in unserem Arbeitsordner zusätzlich eine Datei config.py mit dem folgenden Inhalt.
CSVKWARGS={'delimiter': ',', 'quotechar': '"'}
CSVENCODING='UTF-8'
MANIFEST = {
"preview": {
"url": "http://localhost:5000/preview/{{id}}",
"width": 400,
"height": 300
}
}
Anschließend können wir mit aktivierter virtueller Umgebung in unserem Arbeitsordner den lokalen Reconciling Service für die “Bundesländer Motto” CSV-Datei initiieren und starten.
(venv) > csv-reconcile init --config config.py bundeslaender-motto.csv ID Bundesland
(venv) > csv-reconcile serve
Wenn wir mit dieser Datei fertig sind, können wir den lokalen Reconciling Service für die “Bundesländer Hauptstadt” CSV-Datei initiieren und starten.
Ob die virtuelle Umgebung aktiv ist, sieht man an der Ergänzung (venv) in der Shell.
Ansonnsten lässt sie sich mit .\venv\Scripts\activate wieder aktivieren.
(venv) > csv-reconcile init --config config.py bundeslaender-hauptstadt.csv ID Bundesland
(venv) > csv-reconcile serve
SERVER_NAME in der config.py jeweils einen anderen Port setzen.In OpenRefine fügen wir den lokalen Reconciliation Service hinzu, indem wir in einem Projekt über ein beliebiges
“Spaltenmenü"
"Reconcile"
"Start reconciling” aufrufen und dort via “Add Standard Service…”
die Adresse http://localhost:5000/reconcile eingeben.
Der Port 5000 muss entsprechend angepasst werden, wenn er in der config.py geändert wurde.
Siehe auch die OpenRefine-Dokumentation zu Reconciling: Getting started.
Zusammenführen via ID
Idealerweise haben wir eine eindeutige ID-Spalte, um die Projekte miteinander abzugleichen. Dann ist der lokale Reconciliation Service fast schon etwas zu mächtig, und wird von uns eher eingesetzt, wenn wir es vermeiden wollen, zu viele OpenRefine-Projekte zu jonglieren.
Nachladen des Mottos
Wir haben den lokalen Reconciling Service für das “Bundesländer Motto”-Projekt, wie im oberen Abschnitt beschrieben, am laufen.
Zum Nachladen des Mottos der Bundesländer gehen wir im “Bundesländer”-Projekt über das Spaltenmenü “ID" "Reconcile" "Use values as identifiers” und wählen unseren CSV Reconciliation Service aus.
Die IDs werden nun alle zu Links. Wie im Maus-Hover in Abbildung 12 sehen wir, dass nicht alle IDs aufgelöst werden, sondern manchmal eine “Nicht gefunden” Meldung angezeigt wird. Zur Erinnerung: es gibt nicht für alle Bundesländer ein Motto in unseren Daten!
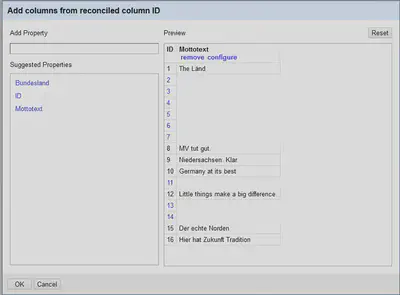
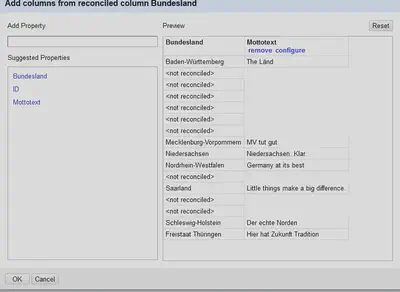
Den Mottotext können wir über “ID" "Edit column" "Add columns from reconciled values…” nachladen. Wie in Abbildung 13 zu sehen ist, kann der Dienst auch mit nicht auflösbaren IDs umgehen und ignoriert diese einfach.
Nachladen der Hauptstadt
Wir haben den lokalen Reconciling Service für das “Bundesländer Hauptstadt”-Projekt, wie im oberen Abschnitt beschrieben, am laufen.
Zum Nachladen der Hauptstädte der Bundesländer gehen wir wieder im “Bundesländer”-Projekt über das Spaltenmenü “ID" "Reconcile" "Use values as identifiers” und wählen unseren CSV Reconciliation Service aus.
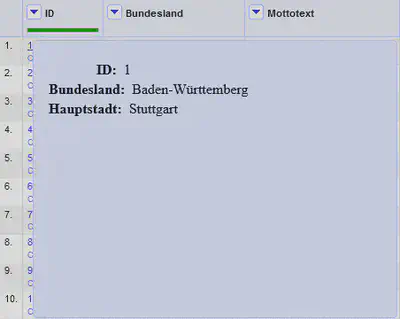
Die IDs werden nun alle wieder zu Links. Bei diesem Abgleich können alle IDs aufgelöst werden und wir sehen wie in Abbildung 14 überall Maus-Hover mit den entsprechenden Werten des gematchten Eintrags in der CSV-Datei.
Zusammenführen via Werte
Es ist nicht immer eine eindeutige ID-Spalte vorhanden. In so einem Fall spielt der lokale Reconciliation Service seine Stärke aus, da wir mit ihm auch “ungenaue” Werte finden und matchen können.
Nachladen des Mottos
Wir haben den lokalen Reconciling Service für das “Bundesländer Motto”-Projekt, wie im oberen Abschnitt beschrieben, am laufen.
Zum Nachladen der Mottos der Bundesländer über die Wertespalte gehen wir zu “Bundesland" "Reconcile" "Start reconciling” und wählen den “CSV Reconciling Service” aus.
Wie in Abbildung 15 markiert, ist das automatische Matching etwas zu großzügig, so dass Bundesländer gematcht werden, weil sie zum Beispiel beide den Begriff “Freistaat” im Namen haben. Das kann manuell und bei größeren Datenmengen mit der Unterstützung von Facets auf den Konfidenzwerten (Wert wie gut das Matching passt) nachgearbeitet werden.
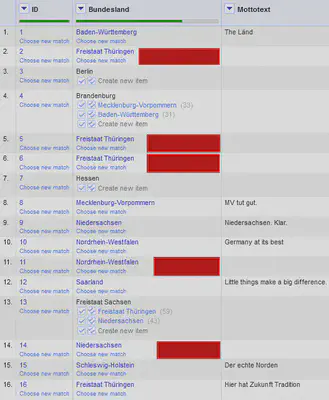
Den Mottotext können wir dann wieder über “Bundesland" "Edit column" "Add columns from reconciled values…” nachladen. Wie in Abbildung 16 zu sehen ist, kann der Dienst auch in diesem Fall mit nicht auflösbaren IDs umgehen und ignoriert diese einfach.
Nachladen der Hauptstadt
Wir haben den lokalen Reconciling Service für das “Bundesländer Hauptstadt”-Projekt, wie im oberen Abschnitt beschrieben, am laufen.
Zum Nachladen der Hauptstädte der Bundesländer über die Wertespalte gehen wir zu “Bundesland" "Reconcile" "Start reconciling” und wählen den “CSV Reconciliation Service” aus.
Da wir in diesem Datensatz passende Einträge für alle Bundesländer haben, funktioniert das Matching, wie in Abbildung 17 zu sehen ist, recht gut, obwohl die Bundesländer teilweise anders geschrieben sind.
Ergebnis
Der Abgleich mit dem lokalen Reconciling Service hat initial einen höherne Aufwand,
da sowohl Python auf dem System als auch der CSV Reconciling Service in OpenRefine eingerichtet werden müssen.
Dann ist das Verfahren jedoch deutlich flexibler als das Zusammenführen mit cross(),
da darüber sowohl ein exaktes ID Matching und Nachladen von Spalten durchgeführt werden kann,
als auch ein so genanntes Fuzzy-Matching, bei dem die Werte in den Spalten nicht exakt übereinstimmen.
In Abbildung 18 sind nochmal alle nachgeladenen Spalten abgebildet, wobei
- via
cross()auf der ID-Spalte - via
cross()auf der Werte-Spalte (Namen Bundesland) - via lokalem Reconciling Service auf der ID-Spalte
- via lokalem Reconciling Service auf der Werte-Spalte (Namen Bundesland)
nachgeladen wurde.

Ausblick auf weitere Methoden
Für das Zusammenführen von Datensätzen mit OpenRefine gibt es noch weitere Möglichkeiten, die sich aktuell in der Planung und Entwicklung befinden.
Zum einen gibt es Überlegungen
für Projekte in OpenRefine automatisch einen Reconciliation Service zu erstellen,
so dass analog zu cross() direkt innerhalb von OpenRefine ein Reconciling gegen andere Projekte durchgeführt werden kann.
Also Reconciling innerhalb von OpenRefine ohne separaten lokalen Reconciling Service.
Zum anderen gibt es mit Datasette ein komplettes Ökosystem um Daten in SQLite einzulesen und anschließend via unterschiedlicher APIs zur Verfügung zu stellen. Es wird gerade auch ein Reconciliation Plugin für Datasette entwickelt.
Gibt es in Arbeitsgruppen Datensätze, die intern oder extern veröffentlicht und auch für Reconciliation genutzt werden sollen, dann lohnt sich ein Blick auf dieses Werkzeug.
Fazit
OpenRefine bietet mit seiner Architektur das Potential zukünftig kollaboratives Arbeiten zu ermöglichen.
Bis dahin können wir uns selbst helfen und mit wenig Extraaufwand Aufgaben aufteilen und die Ergebnisse wieder zusammenführen.
Mit der cross() Funktion können wir direkt Daten aus anderen OpenRefine-Projekten über ID-Spalten übernehmen.
Mit einem lokalem Reconciling Service können wir auch Daten aus unterschiedlichen Projekten verbinden.
Bisher klappt das beschriebene Vorgehen im FDMLab ganz gut und wir beobachten weiterhin gespannt die Entwicklung sowohl von OpenRefine, als auch von anderen Werkzeugen wie csv-reconcile und Datasette, die es hervorragend ergänzen.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.