Clustering von Namen mit OpenRefine
 Photo by Cesar Carlevarino Aragon on Unsplash.
Photo by Cesar Carlevarino Aragon on Unsplash.In diesem Artikel betrachten wir die Clustering Verfahren von OpenRefine im Kontext der Aufarbeitung der Indices der Prokuratoren der Akten des Reichskammergerichts.
Clustern von Prokuratoren
In unserem Artikel Erfahrungsbericht - Extraktion und Abgleich von Prokuratoren mit OpenRefine berichteten wir bereits, dass wir die Deduplikation der Prokuratoren mit unterschiedlichen Schreibweisen über 10 Bände, mit den in OpenRefine integrierten Clustering Verfahren durchgeführt haben.
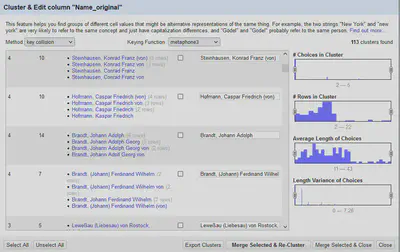
Um die Namen zusammenzuführen, fassen wir zuerst die gleich geschriebenen Namen in Cluster zusammen und suchen anschließend mit den in OpenRefine verfügbaren Clustering Verfahren ähnlich geschriebene Namen (Deduplizierung).
Da wir unterschiedliche Arten von Duplizierungen hatten, verwendeten wir mehrere der angebotenen Verfahren nacheinander, bis wir keine Cluster mehr automatisiert finden konnten.
Dieses Vorgehen ist zwar pragmatisch, jedoch nicht sehr wissenschaftlich. Daher nutzen wir den entstandenen Datensatz, um damit die einzelnen Clustering Verfahren von OpenRefine genauer zu betrachten.
Informationen zum Datensatz
Daher sind die Erkenntnisse in diesem Artikel nur bedingt übertragbar!
Wir haben 2.813 Einzeleinträge (Namen), aus 10 Datenquellen (Findbücher), die wir zu 472 Cluster (Prokuratoren) zusammengefasst haben. In Abbildung 2 ist eine Verteilung der Cluster Größen gezeigt. Also wie viele der 472 Cluster am Ende 1, 2, …, 10 Namen haben.
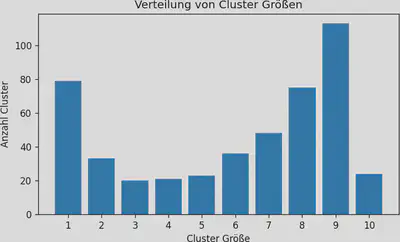
In Abbildung 2 ist zu sehen, dass es nur wenig Prokuratoren gibt, die in allen 10 Bänden erwähnt werden. Wobei hier auch berücksichtigt werden sollte, dass es bei dem relativ kleinen Bestand der Akten des Reichskammergerichts im Staatsarchiv Wertheim - Inventar des Bestands R J 10 insgesamt nur 37 Prokuratoren gibt. Laut Histogramm gibt es circa 80 Prokuratoren, die jeweils nur in einem Band vorkommen.
Insgesamt war die Schreibweise über die Bände relativ einheitlich, so dass nur etwa 10 Prozent der Einträge eine abweichende Schreibweise in einem anderen Band aufwiesen. Diese konnten also schon durch Sortieren in Cluster zusammengeführt werden. Innerhalb der Bände gab es drei Duplikate, also Prokuratoren, die im Index eines Bandes in unterschiedlicher Schreibweise mehrfach erwähnt wurden.
Probleme im Datensatz
Bei der Deduplizierung fanden sich verschiedene Problemtypen, die zu unterschiedlichen Schreibweisen in den einzelnen Bänden geführt haben. Die folgenden Fälle werden in der anschließenden Diskussion näher besprochen:
- Andere Buchstaben: B(u|o)ntz, Jose(f|ph)
- Kurzformen: Antonius, Johannes
- Fehlende Zweitnamen: Speckmann, Johann Stefan
- Fehlende Namensbestandteile:
- Albrecht (von Lauterburg), Johann Konrad
- Heeser, Johann Konrad von
- Alternative Schreibweisen:
- Greck (Gregk), Leo
- Brandt, ( Johann ) Ferdinand Wilhelm
- OCR oder Tippfehler: (Fl|H)einrich, Seche(i|l)
Verfügbare Clustering Verfahren
In OpenRefine werden 8 Cluster Methoden angeboten, die in der Dokumentation zu den Clustering Verfahren erklärt und im OpenRefine GitHub Wiki vertieft werden. Diese Clustering Verfahren lassen sich in drei Arten aufteilen.
Bei den aufwendiger zu berechnenden Nearest-Neighbor Verfahren, wird die Distanz zwischen zwei Namen berechnet. Zum Beispiel haben Buntz und Bontz eine Levenshtein-Distanz von eins (u durch o ersetzen). Diese Distanzen werden anschließend verwendet, um alle “Nachbarn” innerhalb eines bestimmten Radius zu einem Cluster zusammenzufassen.
Bei den allgemeinen Fingerprinting Methoden, werden die Wörter normalisiert und sortiert, bevor sie miteinander abgeglichen werden. Beim n-gramm Fingerprinting werden statt Wörtern Buchstabengruppen verwendet.
Bei den sprachspezifischen Fingerprinting Methoden (Phonetisches Clustering), werden zusätzlich Buchstaben(gruppen) berücksichtigt, die ähnlich ausgesprochen werden. So wurde metaphone3 für die englische Aussprache und cologne-phonetic für die deutsche Aussprache entwickelt. Daitch-Mokotoff und Beider-Morse sind beide auf die jiddische und slawische Aussprache spezialisiert.
Theoretisch sollten in unserem Fall cologne-phonetic, sowie die Nearest-Neighbor Methoden gute Ergebnisse erzielen. Die allgemeinen Fingerprinting Methoden lösen Probleme, die wir in unseren Daten eher nicht haben, wie unterschiedliche Reihenfolge der Namen oder unterschiedliche Interpunktion, Groß- und Kleinschreibung, Akzente,…
Durchführung des Clusterings
Zuerst führen wir den Original Datensatz mit den Prokuratoren aus den Findbüchern und den fertig deduplizierten und mit der GND abgeglichenen Datensatz zusammen. Hierbei ist uns aufgefallen, dass es bei der Bearbeitung mit OpenRefine praktisch gewesen wäre eine ID-Spalte aus dem Original Datensatz mitzuführen, so dass der Ausgangsdatensatz einfacher wieder mit dem Ergebnis zusammengeführt werden kann.
Anschließend legen wir für jede der in OpenRefine verfügbaren Clustering Methoden eine eigene Spalte an. Mit dieser Clustering Methode werden die Namen in der Spalte so lange zusammengeführt, bis sie keine weiteren Cluster mehr findet. Das war bei den meisten Methoden (Ausnahme: Nearest-Neighbor Methoden) nach dem ersten Durchlauf der Fall.
| Verfahren | Runde | Cluster | Parameter |
|---|---|---|---|
| levensthein | 1 | 78 | Radius 1.0, Block Chars 6 |
| 2 | 1 | Radius 1.0, Block Chars 6 | |
| ppm | 1 | 160 | Radius 1.0, Block Chars 6 |
| 2 | 14 | ||
| 3 | 1 | ||
| fingerprint | 1 | 29 | |
| ngram-fingerprint | 1 | 27 | Size 2 |
| metaphone3 | 1 | 113 | |
| cologne-phonetic | 1 | 101 | |
| Daitch-Mokotoff | 1 | 112 | |
| Beider-Morse | 1 | 69 |
Es werden alle Vorschläge für Cluster übernommen. Es werden keine Cluster manuell bearbeitet oder geprüft. Dadurch werden auch Falsch-Positive erzeugt, also Namen von unterschiedlichen Prokuratoren automatisch zusammengeführt. 1
Wir nehmen an, dass in einem realen Anwendungsfall Falsch-Positive zwar einen extra Bearbeitungsaufwand beim Prüfen der Cluster Vorschläge erzeugen, jedoch gut erkannt und vor der Zusammenführung entfernt werden können. Problematischer sind in unserem Fall Falsch-Negative. Also Namen des gleichen Prokurators, die von den Clustering Verfahren nicht erkannt und daher manuell gefunden und zusammengeführt werden müssen.
Ergebnisse
Zur Bewertung der Ergebnisse verwenden wir verschiedene Metriken zur Cluster Performance Analyse von scikit-learn, als auch die Trefferquote (hit_rate).
Bei der Trefferquote bewerten wir lediglich Falsch-Negative als Fehler, da wir davon ausgehen, dass Falsch-Positive bei der manuellen Prüfung der Cluster Vorschläge aussortiert werden. Die von scikit-learn angewendeten Bewertungsmetriken versuchen die Ähnlichkeit zwischen den erzeugten und den gewünschten Cluster zu bewerten.
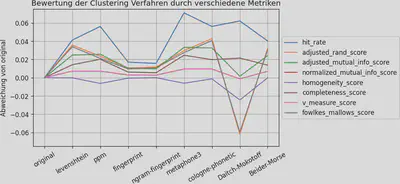
Das Diagramm in Abbildung 3 zeigt die Abweichung der Bewertung für die einzelnen Clustering Verfahren von original an. Dabei beinhaltet original die Cluster, die man durch Sortieren und direktes Zusammenführen von exakt gleich geschriebenen Namen erhält.
Eine Abweichung größer Null bedeutet, dass durch das Clustering Verfahren eine Verbesserung eingetreten ist. Eine Abweichung kleiner Null bedeutet, dass durch viele Falsch-Positive eine Verschlechterung eingetreten ist.
Es ist zu sehen, dass die hit_rate als Bewertungsmetrik die Clustering Verfahren Daitch-Mokotoff, metaphone3 und ppm überschätzt, da sie nur Falsch-Negative als Fehler bewertet.
Prinzipiell scheinen auf unserem Datensatz cologne-phonetic und levenshtein ergänzt durch metaphone3 und ppm einen guten Kompromiss darzustellen.
Diskussion
Die Ergebnisse entsprechen in etwa unseren Erfahrungen beim unreflektierten Ausprobieren der verfügbaren Clustering Verfahren. Mit cologne-phonetic konnten wir im Vergleich zu metaphone3 relativ schnell Namen mit wenigen Falsch-Positiven zusammenführen und dann mit den anderen Verfahren noch fehlende Zusammenführungen vornehmen.
Cluster Visualisierung
Um die Wirkung einzelner Clustering Verfahren auf einzelne Cluster zu visualisieren, haben wir diese mit so genannten Tree Maps dargestellt.
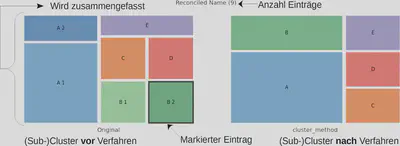
Auf der linken Seite werden zu einem Cluster gehörige Namen dargestellt. Gleich geschriebene Namen werden zu Sub-Clustern zusammengefasst, was unserer “Original” Ausgangsbasis entspricht. Je mehr Namen ein Sub-Cluster hat, desto größer wird er dargestellt.
Auf der rechten Seite sind Sub-Cluster dargestellt, wie sie nach dem Anwenden des Clustering Verfahrens bestehen. Dabei sind Cluster, die von diesem Clustering Verfahren zusammengefasst werden, in der gleichen Farben gehalten. Also Sub-Cluster in einem blauen Farbton auf der linken Seite sind rechts in einem Cluster mit blauer Farbe zusammengefasst.
Spezielle Sub-Cluster sind auf der linken Seite durch eine Umrandung markiert. Wird ein Clustering Verfahren visualisiert, dann handelt es sich bei dem markierten Sub-Cluster um ein Beispiel, das ausschließlich von diesem Verfahren zusammengeführt werden konnte. Wird kein Clustering Verfahren visualisiert, dann handelt es sich bei dem markierten Sub-Cluster um ein Beispiel, das von keinem Clustering Verfahren zusammengeführt werden konnte.
Der Titel des Diagramms enthält den Namen, wie er manuell für das Cluster festgelegt wurde, und die Anzahl an Gesamteinträgen des Clusters.
Andere Buchstaben
B(u|o)ntz, Jose(f|ph)
Für dieses Problem können besonders die phonetischen Clustering Verfahren eingesetzt werden. Wir konnten in unserem Datensatz keine übrig gebliebenen Sub-Cluster mit (ausschließlich) diesen Fehlern finden.
Kurzformen
Antonius, Johannes
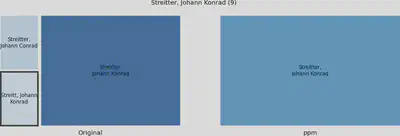
Das Prediction by Partial Matching Verfahren war im Vergleich zu den anderen Verfahren besonders erfolgreich bei der Zusammenführung von Kurz- und Langformen. Es war das einzige Verfahren, dass zum Beispiel den Nachnamen Streitter zusammenführen konnte.
Fehlende Zweitnamen
Speckmann, Johann Stefan

Hier kommt es auf die Länge des Gesamtnamens an. Manchmal konnten kurze fehlende Zweitnamen ignoriert werden. In diesem Beispiel hat der im Verhältnis recht lange Zweitname “Johann” dazu geführt, dass “Speckmann, Stefan” separat blieb und von keinem der Clustering Verfahren mit “Speckmann, Johann Stephan” zusammengeführt wurde. Diesen Namen haben fanden wir, indem wir die Liste alphabetisch sortiert und dann manuell geprüft haben.
Fehlende Namensbestandteile
- Albrecht (von Lauterburg), Johann Konrad
- Heeser, Johann Konrad von

Das fehlende von war für die meisten Verfahren nicht problematisch. Auch die fehlenden Zweitnamen Maria Joseph konnten von mehreren Verfahren kompensiert werden.
Problematisch war hier der relativ lange Einschub von Lilienthal, der dafür sorgte, dass kein Verfahren das Cluster vollständig zusammenfügen konnten.
Alternative Schreibweisen
- Greck (Gregk), Leo
- Brandt, ( Johann ) Ferdinand Wilhelm
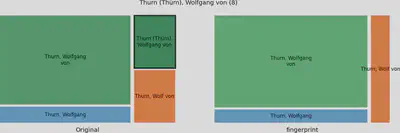
Da beim Fingerprinting eine Normalisierung durchgeführt wird, bei der auch Klammern und Umlaute normalisiert werden, konnte hier die alternative Schreibweise “Thürn” mit “Thurn” zusammengeführt werden. Dies ist jedoch ein Spezialfall. Mit diesem Problemtyp hatten wir in unserem Datensatz die meisten Probleme.
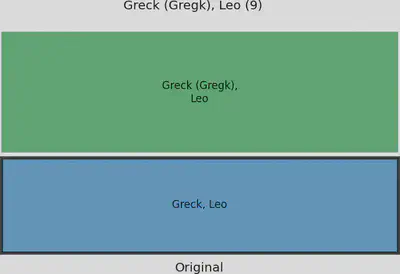
Zum Beispiel hat der Zusatz (Gregk) in Kombination mit den kurzen Namen dazu geführt, dass diese beiden Cluster von keinem Verfahren zusammengeführt werden konnte.
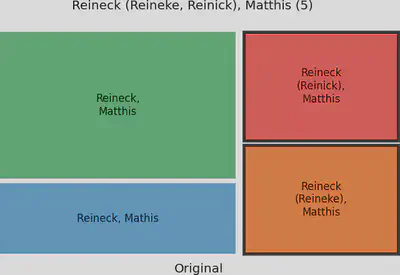
Auch bei Reineck hat der relative hohe alternative Namensbestandteil im Namen dafür gesorgt, dass das Cluster von keinem Verfahren vollständig zusammengeführt werden konnte.
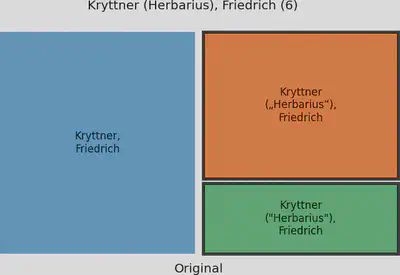
Hier haben wir zusätzlich zu dem alternativen Namen in Klammern auch noch unterschiedliche Anführungszeichen, die je nach Verfahren zusätzliche Probleme erzeugen, wenn sie im Vorfeld nicht normalisiert werden.
OCR oder Tippfehler
(Fl|H)einrich, Seche(i|l)
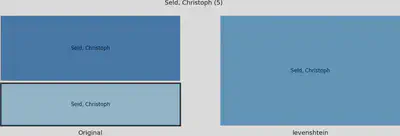
Die (phonetischen) Fingerprint Verfahren haben Probleme mit OCR-Fehlern, wie zum Beispiel die Ersetzung von l durch i. Hier kann ein Nearest-Neighbor Verfahren mit der Levenshtein-Distanz helfen, diese Fälle zusammenzuführen.
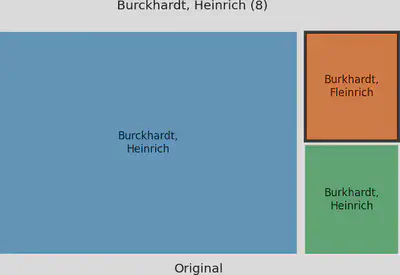
Die unterschiedliche Schreibweise von Burckhardt in Kombination mit dem OCR-Fehler in Fleinrich konnte in den Standardeinstellungen der Clustering Verfahren nicht aufgelöst werden. Hier lohnt es sich mit den Parametern für die Levenshtein-Distanz zu experimentieren (Blockgröße reduzieren und Radius erweitern).
Manuelle Prüfung
Bei der manuellen Prüfung haben wir deutlich mehr Informationen zur Verfügung, als die verwendeten Clustering Verfahren. So nutzten wir zusätzlich die Herkunft des Namens (Band …), Wirkdaten der Prokuratoren, Hinweise auf alternative Schreibweisen durch Verweise im Index der Prokuratoren, Nennung vollständiger Namen im Index der Personen, …
Diese Informationen lassen sich aktuell in OpenRefine nicht automatisiert mitverwenden.
Fazit
Wir haben bei der Analyse der verschiedenen Clustering Verfahren in OpenRefine einiges für unseren Anwendungsfall gelernt:
- Im Vorfeld mehr Data-Cleaning (OCR-Fehler, Sonderzeichen, …)
- Wenn alternative Schreibweisen im Namen kodiert sind, dann diese Kodierungen auflösen und separat clustern (
Greck, LeoundGregk, LeostattGreck (Gregk), Leo). - Für deutsche Texte zukünftig zuerst cologne-phonetic und dann metaphone3 verwenden.
- Anschließend mit Nearest-Neighbor Verfahren in verschiedenen Parametern ergänzen.
- Abschließend die Ergebnisse in sortierter Reihenfolge manuell prüfen.
Aber die wichtigste Erkenntnis:
Clustering mit OpenRefine ist so einfach und funktional, dass wir auch ohne Fachwissen zu einem guten Ergebnis kommen konnten!
Details zu Falsch-Positiven und Falsch-Negativen finden sich im Wikipedia Artikel zur Beurteilung eines binären Klassifikators. ↩︎
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.