Training eines Strukturmodells für Tabellen mit P2PaLA

Transkribus bietet uns gute Werkzeuge an, um das Layout von komplexen Tabellen manuell zu erfassen. Wir möchten aber Bestände mit tausenden von Seiten bearbeiten. Wie können wir die Layoutanalyse auch für komplizierte Tabellenstrukturen automatisieren? Das Tool P2PaLA, welches in die Transkribus-Nutzeroberfläche integriert ist, gibt uns die Möglichkeit, ein spezifisches Strukturmodell für eine Dokumentensammlung zu trainieren.
Unser Anwendungsfall: Stammrollen mit Tabellenlayout
In einem früheren Beitrag haben wir vorgestellt, welche Möglichkeiten Transkribus uns bietet, eine Seite unserer Stammrollen manuell zu segmentieren, um diese für die Texterkennung vorzubereiten. Die Erfahrung zeigte uns: Es funktioniert, aber es kostet auch recht viel Zeit. Transkribus bringt darüber hinaus bereits eine automatische Layoutanalyse mit, die „per Knopfdruck“ ein Ergebnis liefert. In unserem Fall ist die Tabelle jedoch so kompliziert, dass die automatische Analyse kein zufriedenstellendes Ergebnis liefern konnte. Die Stammrollen aus den militärischen Beständen des LABW umfassen insgesamt mehrere Millionen Digitalisate. Da es viel zu aufwändig wäre, tausende von Tabellenseiten händisch zu bearbeiten, möchten wir die Layouterkennung so weit wie möglich automatisieren.
Dazu möchten wir mit dem Tool P2PaLA ein Strukturmodell für das Layout unserer Stammrollen trainieren. Wir wollen uns dabei auf die für uns wesentlichen Informationen konzentrieren und insbesondere die laufende Nummer der Einträge, die Namen der Personen sowie ihre Geburtsdaten erkennen.1 Ein Blick auf das Tabellenlayout zeigt, dass wir diese Informationen in den ersten drei Tabellenspalten finden. Dabei entspricht eine Tabellenzeile einem Eintrag für eine Person.
Die folgende Abbildung zeigt die sechs Tabellenzellen, die wir auf einer Doppelseite erkennen möchten:
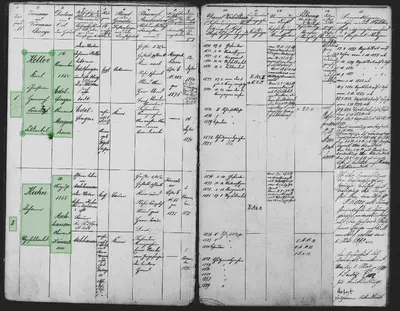
Zusammenstellen eines Trainingsdatensets
Im ersten Schritt muss für das Strukturmodelltraining ein geeignetes Trainingsdatenset zusammengestellt werden. Die Auswahl der Trainingsdaten sollte sorgfältig getroffen werden, denn die spätere Effizienz des Strukturmodells hängt maßgeblich von der Qualität der Trainingsdaten ab. Die Transkribus-Hilfe empfiehlt 50-100 Trainingsseiten, um ein brauchbares Modell zu erstellen. In unserem Fall umfasst das Trainingsdatenset 147 Seiten aus unterschiedlichen Stammrollen der relevanten Bestände.
Sehr wichtig ist, dass die Trainingsdaten wirklich alle Merkmale enthalten, mit denen das Modell später umgehen können soll. Hierbei kommt es durchaus auch auf Kleinigkeiten an: Wenn einige Seiten einen Tabelleneintrag, andere aber zwei Einträge haben, wenn manche Seiten Fußzeilen oder Randbemerkungen aufweisen oder sich auf andere Weise unterscheiden, müssen alle diese Varianten in den Trainingsdaten enthalten sein, damit das Modell sie „erlernen“ kann. Wir haben beispielsweise auch ein paar nicht ausgefüllte Formularseiten und leere, weiße Blätter in unsere Trainingsdaten aufgenommen, da unsere Stammrollen häufig solche Seiten enthalten.
Ein weiterer vorbereitender Schritt ist in unserem Anwendungsfall, dass die Trainingsseiten zunächst zurechtgeschnitten werden müssen. Denn die Digitalisate weisen, da vom Mikrofilm digitalisiert wurde, am oberen Rand einen Streifen mit Verfilmungsinformationen auf. Für das Abschneiden der Bildränder nutzen wir das kostenlose Programm XnView, mit dem auch eine Stapelverarbeitung möglich ist. Alternativ kann für diese Aufgabe auch jedes andere Bildbearbeitungsprogramm genutzt werden.
Erstellung von Ground Truth
Anschließend legen wir für die Trainingsseiten in Transkribus eine Dokumentensammlung an und laden die Seiten in die Sammlung hoch. Wir kennzeichnen auf den Trainingsseiten die relevanten Textteile durch das Einzeichnen von Textregionen um diese Textteile. Wie das genau geht, zeigt die Transkribus-Anleitung. Diese intellektuell geprüften, „richtigen“ Beispiele werden auch als Ground Truth bezeichnet. Sie dienen dem Algorithmus als Referenzmaterial, um die „richtige“ Segmentierung“ unseres Tabellenlayouts zu lernen.
Es hat sich gezeigt, dass man bessere Ergebnisse erzielt, wenn man die Textregionen eher eng um den Text zeichnet, als wenn man den gesamten Zellenbereich inklusive Leerraum kennzeichnet. Unsere Vermutung ist, dass dies darin begründet ist, dass der Algorithmus nach Textbereichen „sucht“ und es deshalb nicht hilft, ihm Tabellenzellen „zeigen“ zu wollen.
Tagging mit Strukturelementen
Über die Registerkarte „Metadata“ legen wir drei benutzerdefinierte Strukturtags „zelle-nummer“, „zelle-name“ und „zelle-geburt“ an. Danach zeichnen wir alle eingezeichneten Textregionen mit dem passenden Strukturtag aus. Eine ausführliche Anleitung zur Verwendung der Funktion des Structural Tagging gibt es auf der Transkribus-Hilfeseite. Die Strukturtags werden wir im nächsten Schritt brauchen, um beim Modelltraining anzugeben, welche Elemente trainiert werden sollen (s.u.).
Durchführung des Modelltrainings mit P2PaLA
Nun können wir das eigentliche Modelltraining mit P2PaLA anstoßen. In der Eingabemaske von P2PaLA wählen wir dafür die drei Strukturtags an, die trainiert werden sollen („zelle-nummer“, „zelle-name“, „zelle-geburt“). Außerdem geben wir dem Modell einen Namen und fügen eine Kurzbeschreibung bei, die erläutert, für welche Dokumente das Modell geeignet ist. Wir trainieren ausschließlich Textregionen und nicht die Erkennung von Textzeilen. Dies reduziert den Aufwand beim Erstellen der Ground Truth deutlich, da für das Training von Zeilen auch die Zeilen manuell gekennzeichnet werden müssten. Anschließend stoßen wir das Training an. Je nach Auslastung des Transkribus-Servers kann es etwas dauern, bis die Ergebnisse eines Trainings vorliegen. Den Status unseres Trainings können wir in der Jobübersicht in der Transkribus-Oberfläche nachverfolgen.
Anwendung des Modells auf Testdaten
Nach Abschluss des Trainings wenden wir unser Stammrollen-Strukturmodell auf ein Testdatenset an, das wir aus fünf Stammrollen zusammengestellt haben, die noch nicht Teil der Trainingsdaten waren, um zu sehen, wie gut das Modell unbekannte Daten tatsächlich verarbeiten kann.
Das Ergebnis zeigt, dass unser Strukturmodell die sechs trainierten Textregionen in allen Stammrollen des Testdatensets findet. Es treten jedoch auch noch Fehler auf. Besondere Seiten, die nicht dem Standard-Layout entsprechen, können nicht erkannt werden, da sie nicht trainiert wurden. Teilweise sind auch auf Seiten, die dem trainierten Layout entsprechen, Fehler zu finden. So wurden stellenweise einzelne Buchstaben oder Wortteile nicht in die Textregion aufgenommen, wenn sie über den Zellenrand hinausragen. Bei Seiten mit einem Eintrag wird die vorhandene Tabellenzeile stets richtig erkannt, manchmal führen Bemerkungen im unteren Seitenbereich aber zu fälschlicherweise eingezeichneten Textregionen.
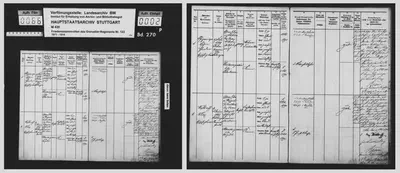
Schlecht erkannt werden Seiten, bei denen die darunterliegenden Seiten noch sichtbar sind oder in die Zettel eingeklebt wurden (siehe Abbildung). Auch durch ein erneutes Training mit zusätzlichen Trainingsbeispielen dieser Art konnte dieses Problem bisher nicht behoben werden.
Wenn im Original die Schrift blass und selbst für das menschliche Auge schwer lesbar ist, wirkt sich dies auch negativ auf die Layoutanalyse aus. Eventuell könnte eine erneute Digitalisierung in höherer Auflösung zu einem besseren Ergebnis führen.

Auf vielen Seiten fanden sich nach der ersten Anwendung unseres Modells sehr kleine Textregionen, die fälschlicherweise an unterschiedlichen Stellen eingezeichnet wurden. Dieses Problem ließ sich sehr leicht beheben, indem wir den minimalen Wert für Textregionen („min area“) in den Einstellungen von P2PaLA heraufgesetzt haben.
Fazit und nächste Schritte
Das Trainieren von Strukturmodellen mit P2PaLA ist für Archive sehr interessant, da die Archive über vielfältige Unterlagen verfügen, die Formulare und Tabellen enthalten. Der beschriebene Anwendungsfall steht daher exemplarisch für viele Anwendungskontexte.
Im FDMLab konnte mit P2PaLA ein Strukturmodell für Stammrollen trainiert werden, welches es ermöglicht, bestimmte, besonders relevante Informationen (laufende Nummer, Namen, Geburtsdaten) zu finden.
Eine noch offene Aufgabe für das FDMLab ist die Automatisierung der richtigen Lesereihenfolge der analysierten Textregionen. Aktuell liest Transkribus die Textregionen spaltenweise von oben nach unten. In unserem Anwendungsfall wünschen wir uns aber ein zeilenweises Auslesen. Transkribus gibt uns die Möglichkeit, die automatisch erstellte Lesereihenfolge nachträglich manuell zu korrigieren. Wir möchten für diesen Schritt jedoch eine maschinelle Lösung finden.
Insgesamt kann gesagt werden, dass wir einen semiautomatischen Prozess realisieren können, da die Ergebnisse unserer Layoutanalyse einer manuellen Nacharbeit bedürfen. Der Aufwand für manuelle Arbeiten ist jedoch sehr viel geringer, als wenn ohne eine automatische Layoutanalyse gearbeitet würde.
Der nächste anstehende Arbeitsschritt wird die Analyse der Textzeilen in den Textregionen sein. Danach wird die eigentliche Handschriftenerkennung durchgeführt werden, die auf Basis der Textzeilen arbeitet.
Es bleibt abzuwarten, wie die Layoutanalyse in Transkribus künftig weiterentwickelt werden wird. Derzeit bietet das Segmentierungsmodul von Transkribus spezielle Funktionalitäten für die manuelle Segmentierung von Tabellen an. Da P2PaLA bisher aber noch keine Tabellenelemente, sondern nur Textregionen erkennen und verarbeiten kann, können diese spezifischen Werkzeuge für das Training von Strukturmodellen leider nicht genutzt werden. Eine Weiterentwicklung der Layoutverarbeitungsmöglichkeiten für Tabellen wäre in hohem Maße wünschenswert.2
Mit Hilfe eines Volltextes, der diese Basisinformationen enthält, kann man die Fundstelle für eine Person schnell recherchieren und weitere Informationen direkt aus der Stammrolle entnehmen. ↩︎
Dies wurde exemplarisch von Naver Labs Europe umgesetzt und sollte in Transkribus integriert werden, jedoch scheint sich die Integration zu verzögern. ↩︎
Elisabeth Klindworth
Archivarin
Ich arbeite daran, maschinelles Lernen in Form automatisierter Erkennung und Annotation digitaler Texte und Bilder in den Archivalltag zu integrieren, um Archivgut noch besser nutzbar zu machen.