Named Entity Recognition mit OpenRefine und spaCy
 Named Entity Recognition mit OpenRefine und spaCy.
Named Entity Recognition mit OpenRefine und spaCy.In diesem Artikel beschreiben wir unsere Versuche mit OpenRefine ein “Named Entity Recognition” mit spaCy durchzuführen, um die Entities anschließend mit der Gemeinsamen Normdatei (GND) abzugleichen.
OpenRefine kann Python Code ausführen. Dann sollte es doch auch möglich sein, damit eine “Named Entity Recognition” mit dem auf Python basierten Framework spaCy durchzuführen. ⚠️ Leider hat es sich gezeigt, dass sich die Umsetzung technischer gestaltet als erwartet.
Da wir uns vornahmen auch negative Erfahrungen zu berichten gehen wir wie folgt vor:
- Wir beschreiben, wie wir uns die Umsetzung vorgestellt hätten.
- Wir erklären, weshalb das nicht funktioniert.
- Wir zeigen eine flexible, dafür technisch aufwendigere Lösung.
Versuch: spaCy in OpenRefine ausführen
OpenRefine bringt mit Jython eine Java Implementierung für Python mit. Theoretisch ist es also möglich das Python Framework spaCy als Python Paket zu installieren und direkt in OpenRefine auszuführen.
Unser gedachtes Vorgehen: wir nehmen an, dass wir auf einem Windows System sind. Dort gehen wir mit dem Dateiexplorer in den OpenRefine Ordner mit integrierter Java Umgebung und öffnen dort eine PowerShell. Dann aktivieren wir mit Jython den Python Paketmanager pip (Zeile 1), installieren spaCy (Zeile 2) und laden ein deutsches Sprachmodell (Zeile 3).
| |
Hätte das funktioniert, könnten wir nun im “expression” Editor zum Beispiel beim Hinzufügen oder Transformieren von Spalten von GREL auf Jython umstellen und mit folgendem Code ein “Named Entity Recognition” mit spaCy auf den Inhalten durchführen.
import spacy
nlp = spacy.load("de_core_news_sm")
doc = nlp(value)
return "\n".join(ent.text + "||" + ent.label_ for ent in doc.ents)
🚫 Leider funktioniert die Installation von spaCy in Jython via pip nicht.
Technische Hintergründe
Jython implementiert aktuell Python in Version 2.7. Seit Januar 2020 wird Python in Version 2 jedoch nicht mehr weiterentwickelt und auch nicht mehr mit Bugfixes versorgt (Status end-of-life). Die aktuelle Version von Python ist Version 3.9.
Entsprechend sind Bibliotheken in aktueller Version häufig auch nur noch mit Unterstützung für Python 3 zu finden. Eine Neuentwicklung von Jython um Python in Version 3 zu unterstützen, oder basierend auf neuer Technologie wie GraalVM nutzbar zu machen, ist nach wie vor in Planung/Umsetzung (siehe Python 3 Roadmap).
Aber auch ältere Versionen von Bibliotheken mit Unterstützung für Python 2 sind nicht einfach via pip zu installieren. Das liegt daran, dass Jython auf Java basiert, viele Python Bibliotheken unter der Haube jedoch Abhängigkeiten zur Programmiersprache C haben.
Alternative: spaCy separat ausführen
Wenn wir spaCy nicht in OpenRefine zum Laufen bekommen, dann können wir es stattdessen separat als Webservice betreiben.
Anstatt einen externen Dienst zu bemühen, wollen wir den Dienst lokal laufen lassen. Dafür packen wir spaCy mit FastAPI in ein API und verwenden Uvicorn als Server.
Python 3.9 installieren
Python 3.9 kann in Form einer ausführbaren Datei (.exe) von Python Downloads heruntergeladen und lokal installiert werden.
Virtuelle Umgebung aufsetzen
Wir erstellen einen Ordner ner-service. In dem Ordner starten wir eine PowerShell.
Dann erstellen wir mit Python eine so genannte virtuelle Umgebung (Zeile 1). 1
Die virtuelle Umgebung aktivieren wir anschließend (Zeile 2), installieren die benötigten Programme (Zeile 3) und laden das Sprachmodell mit spaCy herunter (Zeile 4).
| |
NER Service erstellen
Den folgenden Python Code speichern wir in dem Ordner ner-service in der Datei simple-ner-service.py.
import spacy
import uvicorn
from fastapi import FastAPI, Form
app = FastAPI()
nlp = spacy.load("de_core_news_sm")
@app.post("/ner")
def ner(text: str = Form(...)):
doc = nlp(text)
return [{"text": ent.text, "label": ent.label_} for ent in doc.ents]
if __name__ == "__main__":
uvicorn.run("simple-ner-service:app", host="127.0.0.1", port=5000)
Mit aktivierter virtueller Umgebung können wir den Server mit der PowerShell aus dem Ordner ner-service heraus starten:
| |
NER Service in OpenRefine nutzen
In OpenRefine schicken wir im “expression” Editor den Inhalt einer Zelle (value) mit Jython an den ner-service unter http://localhost:5000/ner und geben das Ergebnis im JSON Format zurück.
Dabei haben wir auf die Kodierung (“encoding”) zu achten, da Python 2 standardmäßig nicht mit UTF-8 arbeitet.
Ein Problem, das in englischsprachigen Anleitungen häufig nicht relevant ist und daher ignoriert wird.
import json, urllib, urllib2
url = 'http://localhost:5000/ner'
request_data = urllib.urlencode({"text": value.encode('utf-8')})
response = urllib2.urlopen(url, request_data)
return json.dumps(json.load(response), ensure_ascii=False)
Die Vorschau des “expression” Editors in OpenRefine zeigt die ersten Ergebnisse.
Zusammenfassung und Erweiterung
Mit etwa 15 Zeilen Python Code haben wir die Daten aus OpenRefine heraus mit einen (lokalen) Service verknüpft, der aufbauend auf der neuesten Technologie eine “Named Entity Recognition” durchführen kann.
Dabei ist der Ansatz so generisch, dass er auf ähnliche Anwendungen übertragen werden kann. Daher haben wir den minimalen Ansatz noch optimiert, dokumentiert und als GitHub Gist zur Verfügung gestellt.
NER mit OpenRefine und spaCy
Mit dem funktionierenden NER Service können wir nun unserer ursprünglichen Idee nachgehen und ein “Named Entity Recognition” mit spaCy durchführen und die “Entities” anschließend mit der Gemeinsamen Normdatei (GND) abgleichen.
NER Service starten
Zuerst starten wir unseren NER Service. Dafür benötigen wir - wie im oberen Abschnitt beschrieben - Python 3 und eine virtuelle Umgebung mit spaCy, FastAPI und Uvicorn. Dort starten wir die Datei ner-service.py aus dem GitHub Gist.
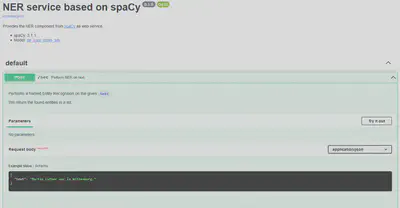
Der NER Service ist nach dem Start unter http://localhost:5000 zu erreichen und kann wie in Abbildung 1 in einer interaktiven Dokumentation auch gleich getestet werden.
OpenRefine Projekt erstellen
Wikipedia Textschnippsel als JSON .💾 Für OpenRefine haben wir einige Textschnippsel aus Wikipedia zusammengesucht (CC-BY-SA-3.0) und bieten diese mit Quellangabe unter gleichen Lizenzbedingungen in einer JSON Datei zum Download an (Rechtsklick und “Ziel speichern unter…”):
Mit der JSON Datei erzeugen wir wie in Abbildung 2 ein neues Projekt in OpenRefine.

Anschließend benennen wir die Spalten zur Übersichtlichkeit in Quelle und Text um.
NER auf Text durchführen
Um eine “Named Entity Recognition” durchzuführen, erzeugen wir eine neue Spalte NER basierend auf der Spalte Text und verwenden wie in Abbildung 3 eine Jython Expression.
import json, urllib, urllib2
url = 'http://localhost:5000/ner'
request_data = json.dumps({'text': value.encode('utf-8')})
request = urllib2.Request(url, request_data, {'Content-Type': 'application/json'})
response = urllib2.urlopen(request)
return json.dumps(json.load(response), ensure_ascii=False)

Informationen aus JSON extrahieren
Um die Informationen aus dem JSON formatierten Text zu extrahieren, verwenden wir die Werkzeuge von GREL. Dafür erzeugen wir wie in Abbildung 4 eine neue Spalte Entity aus der Spalte NER mit einer"expression".
forEach(parseJson(value), v, v.text).join("||")

Für den Typ der Entities erzeugen wir wie in Abbildung 5 eine neue Spalte Label aus der Spalte NER mit einer “expression”.
forEach(parseJson(value), v, v.label).join("||")

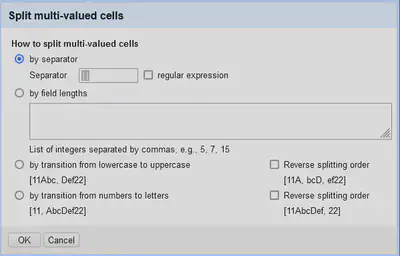
Wir haben nun mehrere Werte in einer Zelle, weshalb wir diese wie in Abbildung 6 mit “Entity"
"Edit Cells"
"Split multi-valued cells…” und “Label"
"Edit Cells"
"Split multi-valued cells…” an der Trennsequenz || auftrennen.
Daten mit GND abgleichen
Nun haben wir die gefundenen Entities in einzelnen Zeilen und können sie nach Belieben bearbeiten, löschen oder mit externen Diensten abgleichen. Dafür verwenden wir den GND Reconciliation Service von lobid. Mit “Entity" "Reconcile" "Start reconciling” starten wir den Abgleichsvorgang. Siehe auch Findbuch Index mit OpenRefine aufbereiten für Details zum Datenabgleich von Daten in OpenRefine mit der Gemeinsamen Normdatei (GND). In Abbildung 7 haben wir einen Screenshot der Daten, nachdem die Entities mit der GND abgeglichen und mit der GND-ID angereichert wurden.

Fazit
In diesem Beitrag haben wir eine Möglichkeit gezeigt, wie generell mit OpenRefine Daten an einen lokalen Service übergeben und verarbeitet werden können. Das haben wir genutzt um ein “Named Entity Recognition” mit spaCy durchzuführen.
Wir hätten uns gewünscht, dass die Integration von Python Frameworks in OpenRefine direkter und weniger technisch zu bewerkstelligen wäre. Andererseits haben wir mit FastAPI eine Framework getestet, mit dem unkompliziert Dienste zur Verfügung gestellt werden können.
Eine virtuelle Umgebung ermöglicht es uns, die für dieses Projekt benötigten Abhängigkeiten direkt in den Ordner zu installieren, und bei Bedarf das komplette Projekt mit allen Abhängigkeiten wieder aufzuräumen. ↩︎
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.