Findbuchdaten mit OpenRefine wiederverwenden
 Aufbereiteten Findbuch Index mit OpenRefine wiederverwenden.
Aufbereiteten Findbuch Index mit OpenRefine wiederverwenden.In diesem Artikel behandeln wir die Frage, wie wir schon aufbereitete Daten mit OpenRefine wiederverwenden können.
Wir haben schon einen Findbuch Index mit OpenRefine aufbereitet. wenn wir nun den Prokuratoren Index von “Band 57: Akten des Reichskammergerichts im Staatsarchiv Sigmaringen - Inventar des Bestands R 7. Bearb. von Raimund J. Weber. Kohlhammer 2004” bearbeiten wollen, dann wäre zu erwarten, dass wir das Projekt nachnutzen können.
Dies ist bedingt möglich. Zum einen können wir die Operationen aus der letzten Findbuchaufbereitung wiederverwenden. Zum anderen können wir die Prokuratoren mit den Prokuratoren aus dem letzten Projekt abgleichen.
Um es vorweg zu nehmen: es hat sich gezeigt, dass wir nur einen Teil der Operationen und Prokuratoren übernehmen können. Aber gerade bei den Operationen ist das eine ziemliche Zeitersparnis.
Index Prokuratoren Akten RKG Band 57Index Prokuratoren Akten RKG Band 57 als OpenRefine ArbeitsschritteProkuratoren Akten RKG Band 57 - Wertheim als CSV💾 Wir benötigen drei Dateien (Rechtsklick und “Ziel speichern unter…”):
Wir möchten explizit dazu einladen diese Dateien zu nutzen, um die einzelnen Schritte in OpenRefine selbst auszuprobieren und damit zu experimentieren.
Operationen übertragen
Mit OpenRefine ist es möglich, die durchgeführten Operationen eines Projektes zu exportieren und in einem anderen Projekt zu importieren. Beschrieben ist das im OpenRefine Manual.
Zuerst erstellen wir das Projekt in OpenRefine mit der Datei akten-rkg-band-57-prokuratoren.txt als Grundlage.
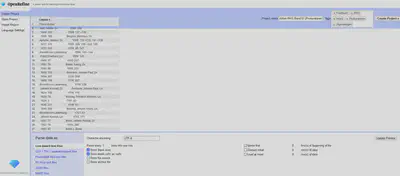
Die Einstellungen sind in Abbildung 1 gezeigt.
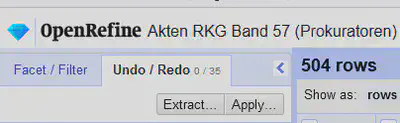
Mit der Schaltfläche “Extract…” bei “Undo/Redo” (siehe Abbildung 2) können wir die Operationen aus einem Projekt exportieren und mit der Schaltfläche “Apply..” anwenden.
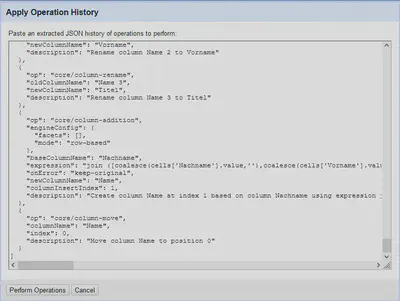
Nach Klicken der Schaltfläche “Apply..” können wir die exportierten Operationen aus akten-rkg-band-57-openrefine-prokuratoren.json wie in Abbildung 3 gezeigt einfügen und mit “Perform Operations” die Operationen auf dem aktuellen Projekt anwenden.
Bei unserem ersten Versuch haben wir festgestellt, dass die Operationen von unserem letzten Artikel nicht direkt auf diesen Index anwendbar sind. Beim Anwenden von Operationen aus einem anderen Projekt sind einige Dinge zu beachten.
- Die
.jsonDatei sollte mit einem Quelltexteditor wie (unter Windows) der Editor App, Notepad++ oder Visual Studio Code geöffnet (und bearbeitet) werden. - Die Spaltennamen in den beiden Projekten müssen die gleichen Namen haben.
- Manuelle Editieroperationen und Filteroperationen werden nicht mit übertragen.
In unserem konkreten Fall gab es zusätzlich die folgenden Probleme
- Die Extraktion der Seitenzahlen funktioniert nicht, da die Kopfzeilen sich unterscheiden.
- Das zweispaltige Layout hat statt 4 einen Minimalabstand von 3 Leerzeichen.
- Es gibt Zeilenumbrüche bei dem Namen der Prokuratoren und bei den Verweisen.
- Die Anpassungen für das “reconciling” lassen sich nicht übertragen.
In der Datei akten-rkg-band-57-openrefine-prokuratoren.json haben wir die Operationen entsprechend bereinigt und angepasst, so dass sie direkt angewendet werden können. In Abbildung 4 ist das Ergebnis der Anwendung zu sehen.
Bei “Albrecht von Lauterbach” ist eine andere Formatierung verwendet worden, die wir manuell nachkorrigiert haben. Dafür sind wir in der “History” der Operationen zurück zu Schritt 33 gegangen. Dann haben wir die fehlerhaften Einträge manuell via “inline editing” korrigiert. Anschließend haben wir die (ehemaligen) Operationen 34 und 35 erneut via “Apply…” angewendet. Die (ehemaligen) Operationen 34 und 35 haben wir hier direkt zum Kopieren in den Artikel eingefügt:
[
{
"op": "core/column-addition",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"baseColumnName": "Nachname",
"expression": "join ([coalesce(cells['Nachname'].value,''),coalesce(cells['Vorname'].value,'')],', ')",
"onError": "keep-original",
"newColumnName": "Name",
"columnInsertIndex": 1,
"description": "Create column Name at index 1 based on column Nachname using expression join ([coalesce(cells['Nachname'].value,''),coalesce(cells['Vorname'].value,'')],', ')"
},
{
"op": "core/column-move",
"columnName": "Name",
"index": 0,
"description": "Move column Name to position 0"
}
]
Zwischenfazit
Die Übertragung von Verkettungen von Operationen, wie zum Beispiel das Auflösen eines zweispaltigen Layouts, ist praktisch und spart dem versierten Benutzer einiges an Zeit. Durch die automatisch generierten Beschreibungstexte für die Operationen ist es jedoch nicht leicht, die entsprechenden Blöcke von Operationen auch zu identifizieren.
Abgleich mit lokaler CSV Datei
Mit der Datei akten-rkg-band-57-wertheim-prokuratoren.csv besitzen wir eine (kleine) lokale Datenbank mit bereits aufbereiteten Prokuratoren.
Diese können wir zum Abgleich mit unseren aufbereiteten Daten in OpenRefine verwenden.
Dafür gibt es Werkzeuge, die eine CSV Datei als “Reconciliation Service” zur Verfügung stellen.
Abgleich mit reconcile-csv (Clojure)
Das Projekt reconcile-csv basiert auf Clojure und lässt sich daher direkt mit der gleichen Java Version ausführen, mit der wir auch OpenRefine verwenden.
Dafür erstellen wir im Ordner mit der openrefine.exe einen Ordner services und kopieren die heruntergeladene reconcile-csv-0.1.2.jar hinein.
In dem Ordner öffnen wir anschließend eine PowerShell und führen mit der Java Version von OpenRefine die .jar Datei aus.
Das CSV Reconciliation Service benötigt drei Parameter:
- Der Pfad zu der CSV Datei.
- Der Name der Spalte mit der abgeglichen werden soll.
- Der Name der Spalte mit einem eindeutigen Wert (ID) für jede Zeile. 1
.\server\target\jre\bin\java.exe -jar .\services\reconcile-csv-0.1.2.jar .\data\akten-rkg-band-57-wertheim-prokuratoren.csv Name Nr
Mit “Name"
"Reconcile"
"Start reconciling” können wir auf der Spalte Name den “Reconciliation” Vorgang starten und dort die Adresse http://localhost:8000/reconcile als “Reconciliation Service” hinzufügen.
Wie in Abbildung 5 gezeigt, gibt es für die einzelnen Ergebnisvorschläge auch eine Vorschau Funktion, in der die Inhalte der Tabellenzeile zum besseren Abgleich angezeigt werden.
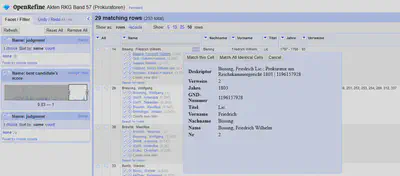
Wir konnten mit dem lokalen Abgleich 28 Prokuratoren aus unserer Liste finden.
An dieser Stelle würden wir gerne weitere Daten aus der CSV Datei laden, wie es von dem von OpenRefine unterstützen Data Extension API angeboten wird. Leider wird diese Funktionalität in diesem Service nicht unterstützt. Da das Projekt Stand August 2021 seit 2015 nicht mehr weiterentwickelt wurde, ist damit auch nicht zu rechnen.2
Abgleich mit csv-reconcile (Python)
Ein neueres Projekt zum Abgleich mit lokalen CSV Dateien ist csv-reconcile, welches auf Python basiert und sich aktiv in der Entwicklung befindet.
Wie wir schon im Artikel Named Entity Recognition mit OpenRefine und spaCy festgestellt haben, ist die Verwendung von Python Frameworks mit OpenRefine aufwendiger, da wir dafür zusätzlich eine aktuelle Python Installation benötigen.
Haben wir lokal Python installiert, dann können wir mit PowerShell im gleichen services Ordner wie im letzten Abschnitt
eine virtuelle Python Umgebung anlegen (1),
diese virtuelle Umgebung aktivieren (2),
das Paket csv-reconcile mit pip installieren (3),
und den “CSV Reconciliation Service” starten (4).
| |
Leider konnte unsere CSV Datei auf Grund ihres Formates und Kodierung nicht auf Anhieb richtig geladen werden, so dass wir zusätzlich eine Konfigurationsdatei config.py mit dem folgenden Inhalt im Ordner services hinterlegt haben.
CSVKWARGS={'delimiter': ',', 'quotechar': '"'}
CSVENCODING='UTF-8'
Der “CSV Reconciliation Service” ist anschließend unter http://localhost:5000/reconcile erreichbar.
Das Python Projekt ist deutlich flexibler und ausführlicher zu konfigurieren, als das ältere Clojure Projekt.
Es unterstützt auch die “Data Extension API”, so dass wir nach dem Abgleich weitere Spalten aus der CSV Datei nachladen können.
Leider fehlt noch eine Vorschau, so dass kein visueller Abgleich zum Beispiel mit den Wirkdaten der Prokuratoren möglich ist.
Ab Version 0.3.0 gibt es eine optionale Vorschau Funktion.
Abgleich mit der GND
Nachdem wir etwa 10 Prozent der Prokuratoren mit unseren lokalen Daten abgleichen konnten, können wir nun den Rest direkt mit der Gemeinsamen Normdatei (GND) abgleichen. Darauf sind wir in Findbuch Index mit OpenRefine aufbereiten genauer eingegangen und werden das daher hier nicht weiter vertiefen.
Fazit
Die Möglichkeit json Schnippsel mit Verkettungen von Operationen für komplexe Aufgaben zu importieren gefällt uns, und wir werden diese Methode gegebenenfalls öfter verwenden.
Für den komfortablen Abgleich mit einer lokalen CSV Datei fehlte den beiden getesteten Bibliotheken noch Funktionalität.
Das auf Clojure basierende reconcile-csv lässt sich ohne großen Mehraufwand verwenden und bietet eine hilfreiche Vorschau Funktion. Ohne eine Unterstützung der “Data Extension API” ist es für unsere Anwendungsfälle aber nur beschränkt nutzbar.
Das auf Python basierende csv-reconcile benötigt eine lokale Python Installation und bietet noch keine Vorschau Funktion, ohne die sich der Datenabgleich teilweise mühsam gestaltet.
Die Möglichkeit eigene Datenbanken in Form von CSV Dateien zu nutzen, oder wie im Falle der Indizes zu den Akten des Reichskammergerichts schrittweise aufzubauen, ist jedoch vorhanden und hat das Potential von großer Arbeitserleichterung.
Da wir bei der Bearbeitung des Prokuratoren Index der Akten in Wertheim nicht alle Prokuratoren mit einer GND-ID verknüpfen konnten, haben wir den Daten eine Spalte Nr mit der “GREL expression”
row.index + 1hinzugefügt. ↩︎Eine Möglichkeit das “Data Extension Problem” zu umgehen, ist aus den abgeglichenen Daten eine neue Spalte mit der “GREL expression”
cell.recon.match.idzu erzeugen und die beiden Dateien anschließend mit einem anderen Werkzeug zusammenzuführen. Eine weitere Möglichkeit besteht darin, die andere CSV Datei in OpenRefine als Projekt zu laden und den Abgleich mit der Funktion cross durchzuführen. ↩︎
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.