Findbücher mit OpenRefine in Datenbank übernehmen
 Vom Findbuch zur Datenbank mit OpenRefine.
Vom Findbuch zur Datenbank mit OpenRefine.In diesem ausführlichen Tutorial wandeln wir mit OpenRefine ein Findbuch zu Akten des Reichskammergerichts in ein AFIS kompatibles Importformat um. Hierbei setzen wir gezielt einfache und verständliche Techniken ein.
Findbuchdigitalisierung
Wir haben im FDMLab unterschiedliche Findbücher digitalisiert und in unser AFIS überführt. Teilweise existierten die Findbücher als Word-Dateien, teilweise als PDF und teilweise ausschließlich als analoge Bücher. Über unseren Workflow beim Digitalisieren von Findbüchern und über die Bedeutung von regulären Ausdrücken bei der Textextraktion haben wir schon berichtet.
Um einen hohen Automatisierungsgrad zu erreichen, haben wir Technologien wie Docker, Jupyter NoteBooks, Python, flairNLP und spaCy eingesetzt.
Das ist sinnvoll, wenn - wie im Fall der Findbücher zu den Akten des Reichskammergerichts - mehrere Findbücher mit ähnlicher Struktur existieren. Die Beherrschung dieser Technologien setzt jedoch technische Grundkenntnisse voraus, deren Aneignung recht zeitintensiv ist.
Daher stellen wir mit OpenRefine eine Möglichkeit vor, wie Findbücher semimanuell für den Import in Datenbanksysteme vorbereitet werden können. Hierbei setzen wir explizit mehr auf nachvollziehbare Schritte und weniger auf automatisierte, universell wiederverwendbare Code-Schnipsel.
Generelles Vorgehen
In diesem Tutorial extrahieren wir das Findbuch “Akten des Reichskammergerichts im Staatsarchiv Wertheim - Inventar des Bestands R J 10” aus dem Anhang von “Band 57: Akten des Reichskammergerichts im Staatsarchiv Sigmaringen - Inventar des Bestands R 7. Bearb. von Raimund J. Weber. Kohlhammer 2004”. Hierbei handelt es sich um 20 Findbucheinträge. Dies ist eine übersichtliche Anzahl für ein Tutorial. Wir haben die Techniken auch mit einem größeren Findbuch mit ca. 400 Einträgen getestet.
Exemplarisch ist der erste Eintrag des Findbuchs in Abbildung 1 gezeigt. Jeder Findbucheintrag ist in die folgenden acht nummerierten Abschnitte eingeteilt: (1) Bestellsignatur und Laufzeit, (2) Kläger, (3) Beklagter, (4) Prokuratoren, (5) Prozessart und Streitgegenstand, (6) Vorinstanzen, (7) Darinvermerk, (8) weitere Angaben. Einige dieser Abschnitte sind optional. Bei dem ersten Eintrag fehlt zum Beispiel der Abschnitt 6 mit den Vorinstanzen.

Die einzelnen Abschnitte enthalten teilweise zusammenhängende Informationsbestandteile (Beklagte, Prokuratoren, Vorinstanzen, …). Teilweise enthalten sie jedoch auch mehrere Informationsbestandteile, wie zum Beispiel im ersten Abschnitt.
1 1 Nr ( C 2145 Altsignatur ) 1597 – 1600 Laufzeit
Vorsignatur: R Rep. 9 Nr. 230 Vorsignatur
Wir gehen bei der Extraktion in mehreren Schritten vor:
- Einträge des Inventars aus Findbuch extrahieren
- Einträge in Abschnitte aufteilen
- Einzelne Informationsbestandteile aus Abschnitten in Tabelle extrahieren
- Einzelne Informationsbestandteile aus Tabelle auf Datenbankschema übertragen
Zur Vollständigkeit: In anderen Findbüchern zu den Akten des Reichskammergerichtes im Landesarchiv BW gibt es noch weitere Informationen, wie zum Beispiel eine separate Bestellsignatur, Schadensbeschreibungen, Literaturhinweise, Hinweise auf Abgabe der Akten an andere Institutionen, … Außerdem gibt es in unserem Erfassungsschema noch weitere Felder, die für alle Findbucheinträge mit einem festen Wert vorbelegt wurden.
Diese Spezialbehandlungen ignorieren wir für dieses Tutorial.
Technische Voraussetzungen
OpenRefine
Bei OpenRefine handelt es sich um ein Excel ähnliches Werkzeug im Browser, mit dem Daten in andere Formate überführt werden können. Details zur Funktionsweise gibt es in der Dokumentation von OpenRefine und in den Erklärvideos zu OpenRefine.
Wir verwenden das Windows kit with embedded Java, mit dem wir ohne Administrationsrechte oder separater Java-Installation direkt loslegen können.
Reguläre Ausdrücke
 von Randall Munroe unter [CC BY-NC Lizenz](http://creativecommons.org/licenses/by-nc/2.5/).](/post/2021-07-findbuecher-mit-openrefine-in-datenbank-uebernehmen/perl_problems_hu0e0484462f33f916343aead87d9b7933_20532_8fdf08fae82e8346817146df2a00337b.webp)
Bei Memes zu regulären Ausdrücken wird wie in Abbildung 2 häufig der Eindruck erweckt, dass sie mehr Probleme erzeugen als sie tatsächlich lösen. Richtig dosiert sind sie jedoch ein hilfreiches Werkzeug bei der Datenextraktion.
Zum Entwickeln, Testen und Verstehen von regulären Ausdrücken, nutzen wir RegEx101 (Alternative: RegExr). Hier bekommen wir wie in Abbildung 3 visuelles Feedback, auf welche Textzeilen unsere regulären Ausdrücke passen und was die einzelnen Bestandteile bedeuten.
 mit Art *ECMAScript*, einem regulären Ausdruck zur Extraktion der **Altsignatur** in der Mitte oben, mehreren Beispielen direkt darunter und hilfreichen Informationen auf der rechten Seite.](/post/2021-07-findbuecher-mit-openrefine-in-datenbank-uebernehmen/regex101_hu03be89b75292a0eb807ee2f1e55d3728_80009_5450a57a227a11af8062f7f9afe0ef8a.webp)
1. Inventar aus Findbuch extrahieren
OpenRefine ist für die Arbeit mit tabellenartigen Strukturen ausgelegt, weshalb es mühsam ist große Texte darin zu formatieren, bzw. längere Abschnitte zu löschen. Daher empfiehlt es sich einige Vorbereitungen zu erledigen, bevor die Daten in OpenRefine geladen werden. Dazu gehört es zum Beispiel das Inventar in einer separaten Datei zu speichern und Abbildungen zu entfernen. Außerdem sollten im Vorfeld ggf. Layout- und OCR-Fehler korrigiert werden. Darauf gehen wir in einem separaten Artikel ein.
In diesem Tutorial betrachten wir den Fall, dass wir auf Basis der originalen Word- oder PDF-Vorlage direkt eine “ordentliche” Textdatei erstellen können.
Inventar Akten RKG Band 57 - Wertheim .💾 Wir stellen die aufgeräumte Datei zur Verfügung (Rechtsklick und “Ziel speichern unter…”):
Wir möchten explizit dazu einladen diese Datei zu nutzen, um die einzelnen Schritte in OpenRefine selbst auszuprobieren und damit zu experimentieren.
2. Einträge in Abschnitte aufteilen
Findbuch laden
Nachdem wir OpenRefine gestartet haben, öffnet sich die Bedienoberfläche im Webbrowser auf http://localhost:3333 automatisch.
Die Sprache der Oberfläche lässt sich auf Deutsch einstellen, wir bleiben jedoch bei Englisch. Das macht es uns einfacher die einzelnen Bedienelemente und Funktionen mit der Dokumentation abzugleichen bzw. via Google Lösungen für Fragestellungen zu finden.
Wie in Abbildung 4 gezeigt, laden wir unter “Create Project” die Textdatei aus dem letzten Abschnitt mit dem Inventar des Findbuchs in OpenRefine.
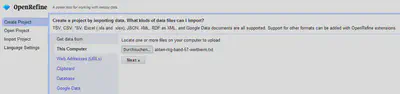
Bei uns hat OpenRefine direkt die passenden Einstellungen für die Datei geladen. Wir haben lediglich den Projektnamen angepasst und Schlagworte (Tags) vergeben. Um das neue Projekt zu erstellen, klicken Sie rechts oben auf den Button “Create Project”. Manchmal möchte OpenRefine davon überzeugt werden, dass wir wirklich eine Textdatei ohne jegliche Tabellenstrukur laden möchten. Dafür wie in Abbildung 5 unter “Parse data as” den Punkt “Line-based text files” auswählen.
Wir haben für uns festgestellt, dass es einfacher ist initial die leeren Zeilen mitzuladen und später zu entfernen. So helfen die leeren Zeilen zum Beispiel bei der visuellen Separierung der einzelnen Findbucheinträge.
Vorbereitungen in OpenRefine
In OpenRefine haben wir nun jede einzelne Textzeile als “row”. Um einen besseren Überblick zu haben benennen wir die (einzige) Spalte in “Original” um und stellen die Anzeige auf “50 rows” um. Zum Umbenennen verwenden wir das Menüsymbol neben der Spaltenüberschrift und gehen in das Untermenü “Edit column" "Rename this column”.
Anschließend wollen wir die Kopfzeilen der ursprünglichen Seiten entfernen.
Diese sehen wie folgt aus (bei den Pfeilen handelt es sich um eine Repräsentation des Unicode Zeichens U+000C für einen Seitenumbruch):
🡹486 Anhang 🡹 Inventar 487
Um diese Zeilen zu entfernen klicken wir auf das Menü-Symbol in der Spalte Original und wählen den “Textfilter”. Dort aktivieren wir das Auswahlkästchen bei “regular expression” (siehe Abbildung 6).
Durch ausprobieren entweder mit RegEx101 oder direkt in dem Feld finden wir heraus, dass der reguläre Ausdruck \d\s+Anhang (Zahl, viele Trennzeichen und das Wort Anhang) alle Zeilen filtert, die wir für die Filterung auf die ursprünglich “linken Seiten” benötigen.
Ein etwas aufwendigerer regulärer Ausdruck wäre \d{3,}\s{4,}Anhang$ (drei oder mehr Zahlen, vier oder mehr Leerzeichen und das Wort “Anhang” am Ende der Zeile).
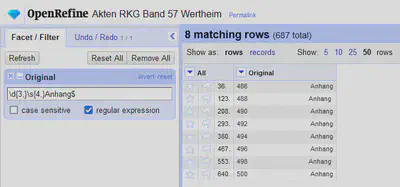
Über das Menü-Symbol neben der Spalte “All” können wir diese Zeilen im Untermenü “Edit rows" "Remove matching rows” entfernen.
Die Kopfzeilen für die ursprünglich rechten Seiten können via Inventar\s+\d bzw. Inventar\s{4,}\d{3,}$ identifiziert und entfernt werden.
Über das Schließen-Symbol am Textfilter kommen wir zur ursprünglichen Ansicht zurück.
Findbuchnummer extrahieren
Neue Spalte anlegen
Als erstes Feld extrahieren wir die Findbuchnummer aus den Textzeilen. Dafür verwenden wir “Original" "Edit column" "Add column based on this column…”.
Wir verwenden die von GREL unterstützten regulären Ausdrücke.
Um die Findbuchnummer zu extrahieren, verwenden wir match auf jeder Zeile (value, siehe Abbildung 7).
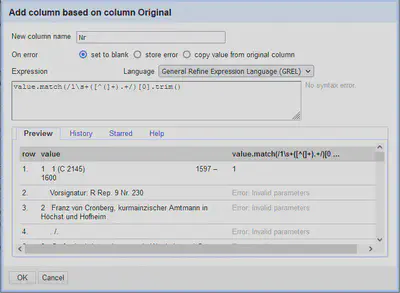
Die verwendete “Expression” filtert Zeilen, die mit 1 und mehreren Leerzeichen beginnen und extrahiert alles direkt nach den Leerzeichen, was keine Klammer ist.
Das anschließende .+ benötigen wir, da der reguläre Ausdruck bei match, anders als bei find, auf die komplette Zeile passen muss.
Von der Liste (technisch Array) der möglichen Ergebnisse wählen wir das erste Ergebnis via [0] und entfernen überflüssige Leerzeichen mit trim.
value.match(/1\s+([^(]+).+/)[0].trim()
Unterschied zwischen rows und records
Die Spalte Nr verschieben wir anschließend ganz an den Anfang via “Nr" "Edit column" "Move column to beginning”. Das hat zur Folge, dass wir nun zwischen “rows” und “records” hin- und herwechseln können. OpenRefine gruppiert die Zeilen anhand der Merkmale in der ersten Spalte in so genannte “records”.
Anstatt der erwarteten 20 Findbucheinträge haben wir jedoch 71?
Also überprüfen wir, ob bei der Extraktion der Findbuchnummern etwas schief gelaufen ist.
Extraktion überprüfen
Um die Extraktion zu überprüfen ohne uns durch alle Seiten zu klicken, verwenden wir ein “Facet” um die entsprechenden Zeilen zu filtern. Dafür verwenden wir “Nr" "Facet" "Text facet”. In dem “Facet” wählen wir “blank” und invertieren die Auswahl oben im “Facet” über “invert” (siehe ABbildung 8).
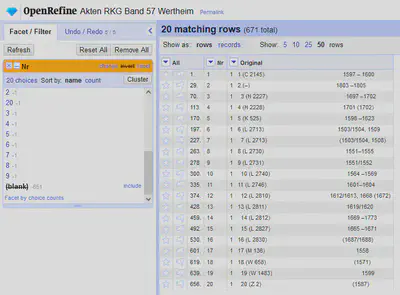
Die Extraktion scheint funktioniert zu haben. Beim genaueren Betrachten der “records” fällt jedoch auf, dass Leerzeilen ebenfalls als “records” gezählt werden.
Leerzeilen entfernen
Es ist also an der Zeit die Leerzeilen zu entfernen. Dafür wechseln wir wieder in die Ansicht “rows” und erstellen ein “Facet” via “All" "Facet" "Facet by blank (null or empty string)”. Im “Facet” wählen wir anschließend “true” und löschen die ausgewählten Zeilen via “All" "Edit rows" "Remove matching rows”.
Wenn wir das “Facet” wieder schließen und nun in die “records” Ansicht wechseln, haben wir genau 20 Einträge.
Abschnittnummer extrahieren
Die Abschnittnummer benötigen wir zwar nicht für unsere Datenbank, sie hilft uns aber die einzelnen Abschnitte mit OpenRefine zu gruppieren und zu bearbeiten.
Analog zur Extraktion der Findbuch Nummer fügen wir eine neue Spalte Abschnitt hinzu (“Original" "Edit column" "Add column based on this column…”) und verwenden die folgende “Expression”:
value.match(/([1-8])\s\s.+/)[0]
Diese Expression filtert Zeilen, die einer Zahl zwischen 1 und 8 gefolgt von zwei Leerzeichen beginnen, und extrahiert anschließend die Zahl.
Die neue Spalte verschieben wir anschließend an den Anfang (“Abschnitt" "Edit column" "Move column to beginning”) und kontrollieren die extrahierten Bestandteile (“Abschnitt" "Facet" "Text facet”). Das “Facet” auf den Abschnittsnummern lassen wir stehen, da wir es später noch benötigen werden.
Zeilen der Abschnitte zusammenfassen
Das Verschieben der Spalte Abschnitt an den Anfang sorgt dafür, dass jeder Abschnitt nun einen eigenen “record” darstellt.
Das ist von daher von Vorteil, da wir alle Zeilen eines “records” in eine Zeile zusammenfassen können.
Dafür verwenden wir “Original"
"Edit cells"
"Join multi-valued cells…”
und geben -:::- als Trennsequenz (“separator”) an. Diese Zeichenfolge verwenden wir, da wir sie anschließend mit einem Zeilenumbruch \n ersetzen wollen.
Ein direktes Verbinden von Zellen mit einem Zeilenumbruch geht in der aktuellen Version (3.5.1) nicht.
Via “Original" "Edit cells" "Transform…” ersetzen wir unsere spezifische Trennsequenz anschließend durch einen Zeilenumbruch.
value.replace("-:::-", "\n")
Wie in Abbildung 9 gezeigt, haben wir nun gleich viele Zeilen (“rows”) wie “records”.
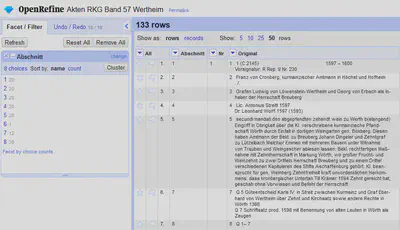
3. Findbuch Inventar in Tabelle umwandeln
Nun können wir den Text Abschnitt für Abschnitt in ein tabellenartiges Format überführen. Das Vorgehen ist prinzipiell immer gleich:
- Mit einer “Expression” eine neue Spalte basierend auf der Spalte Original hinzufügen.
- Eventuell Zeilenumbrüche in der neuen Spalte entfernen.
Abschnitt 1 (Nr, Altsignatur, Vorsignatur, Laufzeit)
In dem “Facet” für den Abschnitt wählen wir den Abschnitt 1.
Die Spalte Nr" haben wir bereits in einem der vorbereitenden Schritte extrahiert. Es folgen die Expressions für die restlichen drei Angaben, die sich noch in Abschnitt 1 befinden, nämlich Altsignatur, Vorsignatur und Laufzeit. Hinzugefügt wird mit “Original" "Edit column" "Add column based on this column…”.
1 1 Nr ( C 2145 Altsignatur ) 1597 – 1600 Laufzeit
Vorsignatur: R Rep. 9 Nr. 230 Vorsignatur
Altsignatur
Die Altsignatur steht in Klammern direkt nach der Findbuchnummer.
Anstatt mit match einen regulären Ausdruck für die komplette Zeile zu definieren, verwenden wir nun find.
value.find(/(?<=\().+?(?=\))/)[0].trim()
Wir suchen eine beliebige Folge von Zeichen, die zwischen zwei Klammern steht. Dafür nutzen wir so genannte “Look-around assertions”. Anschließend wählen wir das erste Ergebnis aus und entfernen vorsichtshalber noch Leerzeichen am Anfang und am Ende.
Alternativ können wir die Klammern auch mit in den regulären Ausdruck aufnehmen und anschließend mit substring entfernen.
value.find(/\([^)]+\)/)[0]
.substring(1, -1)
.trim()
Vorsignatur
Die Vorsignatur steht direkt hinter dem Text “Vorsignatur:”. Dafür können wir eine “positive look-behind assertion” verwenden.
value.find(/(?<=Vorsignatur:).+/)[0].trim()
Alternativ kann auch hier der Text “Vorsignatur:” mit in den regulären Ausdruck aufgenommen und anschließend mit replace entfernt werden.
value.find(/Vorsignatur: .+/)[0]
.replace("Vorsignatur:", "")
.trim()
Das setzt jedoch voraus, dass der Text “Vorsignatur:” auch einheitlich geschrieben wurde. Die Variante mit der “positive look-behind assertion” kann bei unterschiedlichen Schreibweisen einfacher angepasst werden.
Laufzeit
Die Laufzeit steht mit Abstand hinter der eingeklammerten Altsignatur. Also können wir hier als “positive look-behind” nach einer schließenden Klammer, gefolgt von mehreren Leerzeichen suchen, und alle folgenden Zeichen als Laufzeit extrahieren.
value.find(/(?<=\)\s{4}).+/)[0].trim()
Alternativ können wir auch hier die Klammer mit in den regulären Ausdruck aufnehmen und sie anschließend entfernen.
value.find(/\)\s{4,}.+/)[0].substring(1).trim()
Abschnitt 2 (Kläger)
Wir wechseln mit dem “Facet” zu Abschnitt 2 und übernehmen hier den kompletten Inhalt, den wir anschließend bearbeiten.
Wir entfernen die Abschnittnummer am Anfang und das Trennzeichen . /. zwischen Käger und Beklagten.
value.replace(/^2\s{2,}/, "")
.replace(/\n\s*\.\s*\/\./, "")
.trim()
Ab einer bestimmten Menge an Findbucheinträgen gibt es hin- und wieder Unterschiede in der Anzahl der Leerzeichen (Tippfehler, Scanfehler, …), weshalb wir diese dynamisch mit regulären Ausdrücken beschrieben haben. Alternativ hätten wir in diesem Findbuch auch ohne reguläre Ausdrücke arbeiten können.
value.replace("2 ", "")
.replace(". /.", "")
.trim()
Es ist hier auch möglich den Text zu Verkürzen, anstatt die 2 zu ersetzen:
value.substring(1)
.replace(". /.", "")
.trim()
Zeilenumbrüche entfernen
Bei den Klägern wollen wir zusätzlich die Leerzeilen entfernen. Dafür gehen wir auf “Kläger" "Edit cells" "Transform…” und verwenden die folgende Expression:
value.replace(/-\n\s*(?![A-Z])/, "")
.replace(/(?<=-)\n\s*(?=[A-Z])/, "")
.replace(/\n\s*/, " ")
Dieser Expression entfernt zuerst Zeilenumbrüche (mit Bindestrich), die mit einem Bindestrich enden, wobei das erste Wort in der nächsten Zeile nicht groß geschrieben sein darf. Dann werden Zeilenumbrüche entfernt, bei denen der Bindestrich erhalten bleiben soll. Anschließend werden die restlichen Zeilenumbrüche mit einem Leerzeichen ersetzt. Diese Umwandlung können wir wie beschrieben in einem nachgelagerten Schritt, oder direkt bei der Erstellung der Spalte durchführen.
Abschnitt 3 (Beklagte)
Wir wechseln mit dem “Facet” zu Abschnitt 3, übernehmen hier den kompletten Inhalt, entfernen die Abschnittnummer, und entfernen die Zeilenumbrüche.
value.replace(/^3\s{2,}/, "")
.trim()
.replace(/-\n\s*(?![A-Z])/, "")
.replace(/(?<=-)\n\s*(?=[A-Z])/, "")
.replace(/\n\s*/, " ")
Abschnitt 4 (Prokuratoren)
Wir wechseln mit dem “Facet” zu Abschnitt 4 und übernehmen hier den kompletten Inhalt. Die Formatierung (Zeilenumbrüche, …) wollen wir hier beibehalten. Lediglich die Abschnittnummer entfernen wir.
value.replace(/^4/, " ")
Abschnitt 5 (Prozessart und Gegenstand)
Wir wechseln mit dem “Facet” zu Abschnitt 5. Hier wollen wir die Prozessart von dem Prozessgegenstand trennen. Hierfür ist es in den meisten Fällen ausreichend, die erste Zeile von den restlichen zu trennen. Bei manchen Prozessen erstreckt sich die Prozessart jedoch auf mehrere Zeilen. Es ist zwar möglich auf Grund verschiedener Merkmale die Anzahl der Zeilen für die Prozessart zu bestimmen, der Algorithmus dafür wird jedoch komplex. Daher prüfen wir die einzelnen Einträge und korrigieren bei den Ausnahmen manuell nach.
Prozessart
value.split("\n")[0]
.replace(/^5\s{2,}/, "")
.trim()
Wir trennen den Text an den Zeilenumbrüchen auf, wählen die erste Zeile und ersetzen dort die Abschnittnummer. Anschließend korrigieren wir die Prozessart in den Ausnahmefällen manuell. Dafür fahren wir wie in Abbildung 10 mit der Maus in die zu bearbeitende Zelle, worauf ein blaues Bedienelement mit dem Text “Edit” es uns erlaubt in den Bearbeitungsmodus für diese Zelle zu wechseln.
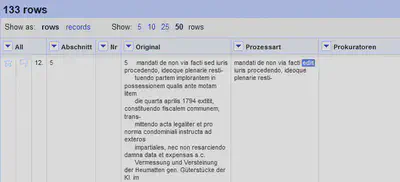
Gegenstand
Die Spalte Prozessart haben wir schon manuell korigiert. Um uns diesen Schritt für die Spalte Gegenstand zu sparen, gehen wir in der nächsten “Expression” wie folgt vor:
- Ersetze die Abschnittnummer
- Ersetze alle Zeilenumbrüche
- Entferne die Prozessart durch Ersetzung mit dem Inhalt der Spalte Prozessart.
value.replace(/^5\s{2,}/, "")
.replace(/-\n\s*(?![A-Z])/, "")
.replace(/(?<=-)\n\s*(?=[A-Z])/, "")
.replace(/\n\s*/, " ")
.replace(cells["Prozessart"].value, "")
.trim()
Abschnitt 6 (Vorinstanzen)
Wir wechseln mit dem “Facet” zu Abschnitt 6 und übernehmen hier den kompletten Inhalt. Die Formatierung (Zeilenumbrüche, …) wollen wir hier beibehalten. Lediglich die Abschnittnummer entfernen wir.
value.replace(/^6/, " ")
Abschnitt 7 (Darin)
Wir wechseln mit dem “Facet” zu Abschnitt 7 und übernehmen hier den kompletten Inhalt. Die Zeilenumbrüche wollen wir entfernen, dabei aber jedes Q in einer neuen Zeile stehen haben.
Dabei gehen wir wie folgt vor:
- Abschnittnummer entfernen
- Zeilenumbrüche vor
Qmit Trennsequzenz ersetzen - Zeilenumbrüche vor
ohne Qmit Trennsequzenz ersetzen - Zeilenumbrüche mit Bindestrich (anschließend Kleinschreibung) entfernen
- Zeilenumbrüche mit Bindestrich (anschließend Großschreibung) entfernen
- Restliche Zeilenumbrüche mit Leerzeichen ersetzen
- Trennsequzenz durch Zeilenumbrüche und Leerzeichen für Formatierung ersetzen
value.replace(/^7/, " ")
.replace(/\s*\n\s+(?=Q\s*\d)/, "-:::-")
.replace(/\s*\n\s+(?=ohne Q\s*)/, "-:::-")
.replace(/-\n\s*(?![A-Z])/, "")
.replace(/(?<=-)\n\s*(?=[A-Z])/, "")
.replace(/\n\s*/, " ")
.replace(/-:::-/, "\n ")
Abschnitt 8 (Umfang, Stapelhöhe, Hinweise)
Wir wechseln mit dem “Facet” zu Abschnitt 8. In diesem Abschnitt haben wir mehrere Bestandteile, die wir in separate Spalten extrahieren wollen.
Q 1– 39
3 cm Stapelhöhe
ohne Wetzlarer Nummer, da vor Generalausteilung abgegeben (an Nach-
folgeinstanz?)
Die Stapelhöhe bietet sich hier als Trennmerkmal an, da sie einfach zu identifizieren ist. Bei Einträgen ohne Stapelhöhe können wir die Trennung manuell vornehmen. Bei komplexeren Angaben können die verwendeten regulären Ausdrücke auch erweitert werden.
Umfang
Um den Umfang zu extrahieren, teilen wir den Eintrag bei der Stapelhöhe und entfernen die Abschnittnummer.
value.split(/\d+\s+cm/)[0]
.replace(/^8\s+/, "")
.trim()
Ein Eintrag muss manuell nachbearbeitet werden.
Stapelhöhe
Die Stapelhöhe extrahieren wir direkt mit einem regulären Ausdruck.
value.find(/\d+\s+cm/)[0]
Hinweise
Die Hinweise stehen nach der Stapelhöhe. Daher teilen wir den Eintrag bei der Stapelhöhe, nehmen den hinteren Teil, und entfernen die Zeilenumbrüche.
value.split(/\d+\s+cm/).slice(1).join("")
.replace(/-\n\s*(?![A-Z])/, "")
.replace(/(?<=-)\n\s*(?=[A-Z])/, "")
.replace(/\n\s*/, " ")
.trim()
Ein Eintrag muss manuell nachbearbeitet werden.
Nacharbeiten
An dieser Stelle ist es soweit, dass wir die Spalten umsortieren, überflüssige Spalten löschen, die Zeilen zusammenfassen und die Daten noch einmal visuell prüfen.
Spalte Abschnitt löschen
Die Spalte Abschnitt wird nicht mehr benötigt und sie kann gelöscht werden. “Abschnitt" "Edit column" "Remove this column”
Zeilen zusammenfassen
Bei der Spalte Original verbinden wir mit der Trennsequenz -:::- über “Original"
"Edit cells"
"Join multi-valued cells…”. Die Trennsequenz ersetzen wir anschließend via “Original"
"Edit cells"
"Transform…”.
value.replace("-:::-", "\n")
Die anderen Spalten (Hinweise, Stapelhöhe, Umfang, Darin, Vorinstanzen, Gegenstand, Prozessart, Prokuratoren, Beklagte, Kläger) verbinden wir ohne Trennzeichen, da es hier ja nur einen Wer pro “record” gibt.
Jetzt sollten wir wieder genausowiele Zeilen (“rows”) wie “records” haben.
Spalten sortieren
Jetzt können die Spalten via “All" "Edit columns" "Re-order / remove columns…” noch sortiert werden.
Visuell inspizieren
Jetzt kommt noch einmal ein visueller Abgleich der extrahierten Daten mit dem Original. Die Spalte Original kann danach auch gelöscht werden (“Original" "Edit column" "Remove this column”). Das Ergebnis ist in Abbildung 11 gezeigt.
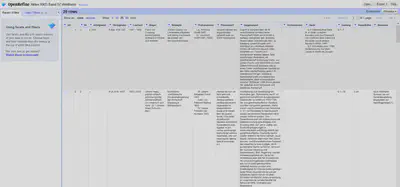
Export
Die Daten können wir über “Export" "Comma-separated value” als CSV-Datei exportieren. Das machen wir, da wir für die Transformation der Daten auf das Datenbankschema ein separates Projekt erstellen wollen.
Diese Trennung in zwei Projekte ist Geschmackssache. Es hat sich jedoch gezeigt, dass es gerade bei der Übertragung der Daten auf das Erfassungsschema Abstimmungsbedarf und gegebenenfalls mehrerer Iterationen bedarf. Daher hat sich diese Aufteilung in zwei getrennte Arbeitsschritte und Projekte bei uns etabliert.
Inventar Akten RKG Band 57 - Wertheim als OpenRefine Arbeitsschritte .💾 Die einzelnen Arbeitsschritte im OpenRefine Format:
4. Tabelle auf Datenbankschema übertragen
Wir haben in Teil 3 den Text des Inventars des Findbuchs in strukturierte Daten umgewandelt. In diesem Teil wandeln wir diese Daten in unser Erfassungs- bzw. Datenbankschema um. Anders ausgedrückt: Wir bringen die Daten in eine Form, die es uns erlaubt, sie auf die Felder unseres Erschließungsformulars im AFIS zu mappen.
Inventar Akten RKG Band 57 - Wertheim als CSV .💾 Die Datei mit den strukturierten Daten für diesen Teil:
Import
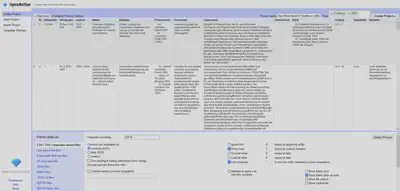
Wir erstellen ein neues Projekt in OpenRefine und importieren dafür die CSV Datei. OpenRefine erkennt automatisch die passenden Einstellungen und wir passen lediglich den Projektnamen und die Schlagworte an. Siehe dazu Abbildung 12.
Transformation
Da wir schon strukturierte Daten haben, fällt dieser Abschnitt etwas kürzer aus. Hier geht es hauptsächlich darum einzelne Spalten zusammenzufassen, gegebenenfalls mit Text zu ergänzen und manchmal auch umzuwandeln.
Titel
Hier wollen wir, dass der Kläger im Titelfeld steht und dass der Titel mit “Kläger:” beginnt. Unser Titel soll also die Form “Kläger: {Kläger}” haben. Dafür wandeln wir die Spalte einfach via “Kläger" "Edit cells" "Transform…” um:
"Kläger: " + value
Anschließend benennen wir die Spalte via “Kläger" "Edit column" "Rename this column” in “Titel” um.
Um die Übersicht zu behalten, verschieben wir diese Spalte mit “Titel" "Edit column" "Move column to end” direkt an das Ende.
Bestellsignatur
Für die Bestellsignatur ergänzen wir zur Findbuch Nummer in der Spalte Nr die Bestandssignatur R J 10.
Dafür transformieren wir via “Nr"
"Edit cells"
"Transform…”
"R J 10 " + value
Danach benennen wir die Spalte via “Nr" "Edit column" "Rename this column” in “Bestellsignatur” um.
Anschließend sind wir mit dieser Spalte fertig und verschieben sie via “Bestellsignatur" "Edit column" "Move column to end” direkt an das Ende.
Vorsignatur 1
Hier können wir direkt die Spalte Altsignatur umbennen und an das Ende verschieben.
Vorsignatur 2
Hier können wir direkt die Spalte Vorsignatur umbennen und an das Ende verschieben.
Entstehungszeitraum
Wir haben beschlossen, dass wir als Entstehungszeitraum die niedrigste Jahreszahl der Laufzeit bis zur höchsten Jahreszahl der Laufzeit verwenden. Diese müssen aus der Laufzeit erst noch extrahiert und in das AFIS Importformat umgewandelt werden.
Um die original Schreibweise zu erhalten, wird diese im nächsten Feld (Entstehungszeitraum, Anm.) übernommen.
Also erstellen wir hier eine neue Spalte aus der Spalte Laufzeit durch folgende Operationen:
- Ersetze alles was keine Ziffer ist
\Ddurch ein Leerzeichen. - Ersetze mehrere Leerzeichen hintereinander
\s+durch ein Leerzeichen. - Entferne Leerzeichen zu Beginn und Ende der Laufzeit mit
trim(). - Teile den Text an Leerzeichen mit
split(). - Sortiere die Liste (technisch ein Array) mit
sort(). - Die Liste wird
arrgenannt (viawith). - Wenn die Liste mehr als ein Element beinhaltet, nehmen wir das erste
arr[0]und letzte Elementarr[-1]aus der sortierten Liste. - Wenn die Liste nur ein Element beinhaltet, nehmen wir dieses.
- (indirekt) Bei Fehlern, wird das Feld einfach nicht ausgefüllt.
with(
value.replace(/\D/, " ")
.replace(/\s+/, " ")
.trim()
.split(" ")
.sort(),
arr,
if(arr.length() > 1,
">=<= +" + arr[0] + " +" + arr[-1],
"= +" + arr[0]))
Anschließend verschieben wir die neue Spalte an das Ende.
Entstehungszeitraum, Anm.
Hier können wir direkt die Spalte Laufzeit umbennen und an das Ende verschieben.
Beklagte
Diese Spalte übernehmen wir direkt so und verschieben sie an das Ende.
Bemerkung
In dieser Spalte fassen wir die Spalten Vorinstanzen und Hinweise zusammen. Hier gibt es mehrere Möglichkeiten die Spalten zusammen zu fassen.
Technische Variante
Bei der ersten, technischeren Variante erstellen wir eine neue Spalte basierend auf der Spalte Vorinstanzen und fügen dabei den Wert der Spalte Hinweise hinzu.
Dabei ist zu beachten, dass wir die Werte nur verwenden, wenn sie auch vorhanden sind isNonBlank.
Sonst kommt es zu einem Fehler und die Zielspalte bleibt leer, wenn zum Beispiel für einen Eintrag nur die Vorinstanzen belegt sind.
Von der Spalte Vorinstanzen ausgehend erzeugen wir eine neue Spalte Bemerkung mit folgender “Expression”:
(
if(isNonBlank(value),
"Vorinstanzen, Anfangsjahr:\n" + value,
"")
+
if(isNonBlank(cells["Hinweise"]),
"\n\nHinweise: " + cells["Hinweise"].value,
""))
.trim()
Anschließend löschen wir die Spalten Vorinstanzen und Hinweise und verschieben die neue Spalte Bemerkung an das Ende.
Weniger technische Variante
Bei der weniger technischen Variante transformieren wir zuerst die Spalte Vorinstanzen:
if(isNonBlank(value),
"Vorinstanzen, Anfangsjahr:\n" + value,
"")
Dann transformieren wir die Spalte Hinweise:
if(isNonBlank(cells["Hinweise"]),
"\n\nHinweise: " + cells["Hinweise"].value,
"")
Anschließend verbinden wir die beiden Spalten via “Vorinstanzen" "Edit column" "Join columns…”. Dabei können wir die Original Spalten Vorinstanzen und Hinweise auch gleich löschen. Siehe dazu Abbildung 13.
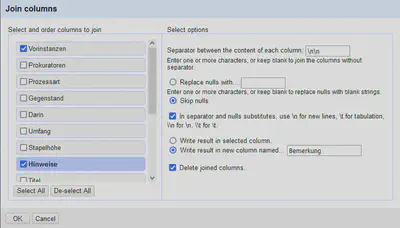
Die neue Spalte Bemerkung schieben wir an das Ende.
Enthält
Hier fassen wir die Spalten Gegenstand, Darin und Prokuratoren zusammen.
Von der Spalte Gegenstand ausgehend erzeugen wir eine neue Spalte Enthält mit folgender “Expression”:
(
if(isNonBlank(value),
"Gegenstand materiell:\n " + value,
"")
+
if(isNonBlank(cells["Darin"]),
"\n\nDarin:\n" + cells["Darin"].value,
"")
+
if(isNonBlank(cells["Prokuratoren"]),
"\n\nProkuratoren mit Bevollmächtigungsjahr:\n" + cells["Prokuratoren"].value,
""))
.trim()
Die Spalten Gegenstand, Darin und Prokuratoren löschen wir anschließend und die neue Spalte Enthält verschieben wir an das Ende.
Gegenstand
Hier können wir direkt die Spalte Prozessart umbennen und an das Ende verschieben.
Umfang
Wir haben uns dazu entschlossen den Umfang und die Stapelhöhe in einem Feld zu erfassen und führen sie daher wieder zusammen.
Um uns das Umbenennen der Spalte Umfang zu sparen, transformieren wir die Spalte anstatt eine neue Spalte zu erzeugen.
(
value
+
if(isNonBlank(cells["Stapelhöhe"]),
"\n" + cells["Stapelhöhe"].value,
""))
.trim()
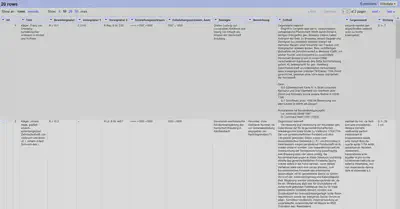
Anschließend löschen wir die Spalte Stapelhöhe und verschieben die Spalte Umfang an das Ende. Die Daten sind nun in ihrem Zielformat und sind in Abbildung 14 abgebildet.
Export
Die Daten werden nun über “Export" "Custom tabular exporter…” als CSV-Datei exportiert. Die Einstellungen sind in Abbildung 15 gezeigt.
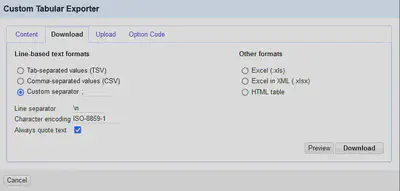
Wir verwenden den “Custom tabular exporter”, da bei uns häufig Excel zum Inspizieren der Daten verwendet wird.
Excel erwartet bei CSV-Dateien jedoch ein Semikolon ; als Trennzeichen und iso-8859-1 als Kodierung.
Inventar Akten RKG Band 57 - Wertheim als CSV für Datenbank Import . > > 💾 Die einzelnen Arbeitsschritte im OpenRefine Format: Inventar Akten RKG Band 57 - Wertheim als OpenRefine Arbeitsschritte .💾 Die Datei mit den strukturierten Daten für den Datenbank Import:
Fazit
Wir haben mit OpenRefine ein komplettes, textbasiertes Findbuch in ein für den Datenbankimport kompatibles Format umgewandelt. Dabei haben wir auf komplexe Code-Schleifen und Bedingungen verzichtet und dafür mehr manuelle Schritte vorgenommen.
Die Fähigkeit von OpenRefine Änderungen an Daten und die Wirkung von Transformationen quasi live anzuzeigen, erlaubt es auch Einsteigern schnelle Fortschritte zu erzielen. Mit den Erklärungen und dem Aufzeigen unterschiedlicher Lösungen haben wir Strategien aufgezeigt, die sich auf ähnliche Probleme übertragen lassen.
Wir konnten zeigen, dass sich mit OpenRefine auch Texte in tabellenartige Formate transformieren lassen. Es bleibt die Herausforderung passende Muster (reguläre Ausdrücke) zu finden, die es ermöglichen die Daten aus den Texten passend herauszufiltern.
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.