Findbuch Index mit OpenRefine aufbereiten
 Text mit OpenRefine aufbereiten und anreichern.
Text mit OpenRefine aufbereiten und anreichern.In diesem Tutorial arbeiten wir mit OpenRefine und der Gemeinsamen Normdatei (GND) den Prokuratoren Index eines Findbuchs zu Akten des Reichskammergerichts auf.
Wir haben bereits beschrieben, wie wir die Einträge eines Findbuchs mit OpenRefine für den Datenbankimport aufbereiten. In diesem Beitrag geht es um die Aufarbeitung eines Indices von Findbüchern. Wir beginnen mit dem Index der Prokuratoren. Andere Indices folgen gegebenenfalls in weiteren Artikeln.
Generelles Vorgehen
Zur Übersichtlichkeit verwenden wir wieder das Findbuch “Akten des Reichskammergerichts im Staatsarchiv Wertheim - Inventar des Bestands R J 10” aus dem Anhang von “Band 57: Akten des Reichskammergerichts im Staatsarchiv Sigmaringen - Inventar des Bestands R 7. Bearb. von Raimund J. Weber. Kohlhammer 2004” mit 20 verzeichneten Archivalien.
Die Findbücher zu den Akten des Reichskammergerichts enthalten verschiedene Indices. Wir behandeln in diesem Tutorial den Index der Prokuratoren.

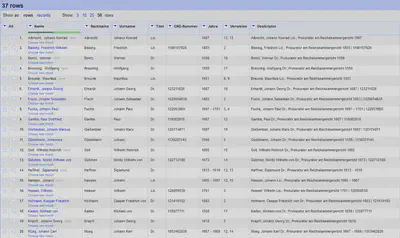
Wie in Abbildung 1 zu sehen, handelt es sich bei dem Index um ein mehrspaltiges Layout, was das Einlesen in OpenRefine verkompliziert. Zu den einzelnen Prokuratoren finden wir eine Zuordnung von Jahren auf die Findbuchnummer(n) der verzeichneten Archivalie(n).
Zur Aufarbeitung des Index gehen wir wie folgt vor:
- Index aus Findbuch extrahieren
- Spalten zusammenführen
- Informationen zu Prokuratoren zusammenführen
- Abgleich mit der Gemeinsamen Normdatei (GND)
- Umwandlung in internes Deskriptorenformat
Dabei werden wir die einzelnen Schritte in OpenRefine nicht so detailliert beschrieben, wie in unserem letzten Tutorial. Bei Bedarf, können Details zu einzelnen Schritten dort noch einmal nachgelesen werden.
1. Index aus Findbuch extrahieren
Auch bei den Indices empfiehlt es sich schon diverse Vorarbeiten im Text selbst durchzuführen.
Index Prokuratoren Akten RKG Band 57 - Wertheim .💾 Wir stellen die aufgeräumte Datei zur Verfügung (Rechtsklick und “Ziel speichern unter…”):
Wir möchten explizit dazu einladen diese Datei zu nutzen, um die einzelnen Schritte in OpenRefine selbst auszuprobieren und damit zu experimentieren.
2. Spalten zusammenführen
Wie in unserem letzten Tutorial erstellen wir mit OpenRefine ein neues Projekt mit “Create Project” und laden die heruntergeladene Datei als Text.
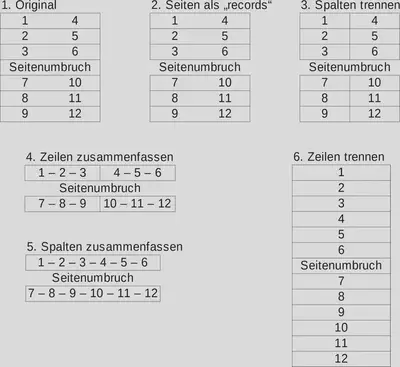
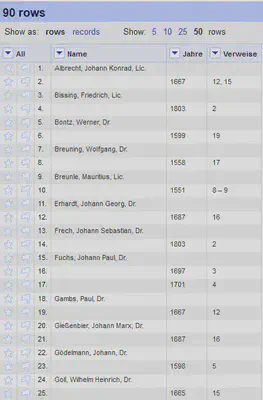
Um das zweispaltige Layout in ein einspaltiges Layout zu überführen, gehen wir wie in Abbildung 2 schematisch dargestellt vor:
- Die Spalte “Column 1” benennen wir in Original um.
- Wir erstellen “records” aus den einzelnen Seiten.
- Wir trennen die Spalten zeilenweise auf.
- Wir fassen die “records” in einer Zeile zusammen.
- Wir fügen die Spalten wieder zusammen.
- Wir trennen die einzelnen Zeilen wieder auf.
1 Spalte in Original umbennen
Die Umbenennung der Spalte Column 1 in Original funktioniert über “Column 1" "Edit column" "Rename this column”.
Der geladene Datensatz sieht ansclhießend wie in Abbildung 3 aus.
2 Seiten als records
Um die einzelnen Seiten als “records” zu markieren, erstellen wir eine neue Spalte Seite via “Original" "Edit column" "Add column based on this column…” und verwenden die folgende “expression” um die Seitennummer auszulesen.
value.match(/.(\d+)\s+Anhang/)[0]
Die Seite 519 tragen wir bei der Indexüberschrift “4. Prokuratoren” von Hand ein. Die leeren Zeilen löschen wir über das “Blank row Facet”, das wir über “All" "Facet" "Facet by blank (null or empty string)” aktivieren.
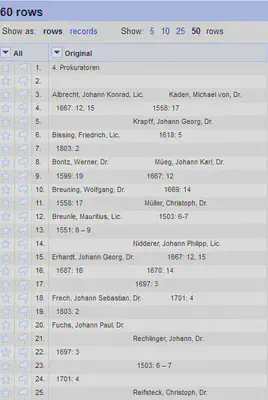
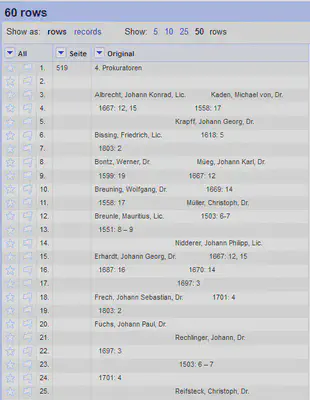
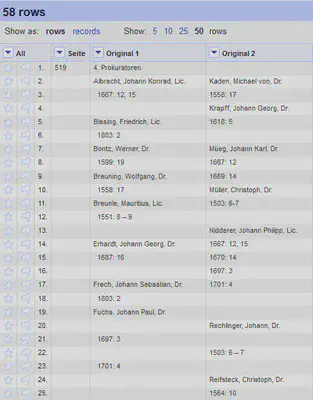
Die Spalte Seite verschieben wir anschließend an die erste Position, um pro Seite ein “record” zu haben. Die nach Seiten organisierten “records” sehen anschließend wie in Abbildung 4 aus.
3 Spalten zeilenweise auftrennen
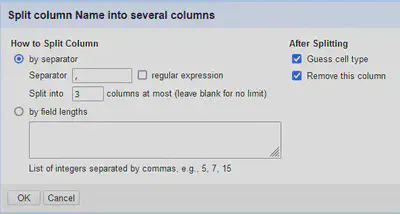
Um die Spalten aufzuteilen, gibt es wie in Abbildung 5 gezeigt mehrere Möglichkeiten. Es ist möglich ein Trennzeichen anzugeben, einen regulären Ausdruck zum Trennen zu verwenden, oder eine feste Spaltenbreite zu definieren.
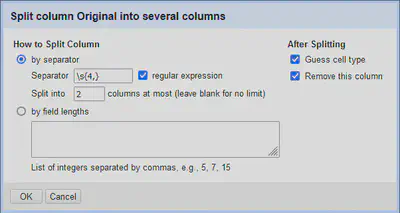
Bei diesem Findbuch funktioniert die Auftrennung nach einer festen Spaltenbreite nicht, da zum Beispiel die linke Spalte auf Seite 519 größer ist als die linke Spalte auf Seite 520.
Also trennen wir an einer Folge von vier oder mehr Leerzeichen auf \s{4,}.
Das hat den Nachteil, dass wir die Einrückungen in der zweiten Spalte verlieren.
Dies stört uns bei diesem Index nicht.
Das Ergebnis ist in Abbildung 6 gezeigt. Anschließend können wir mit “All" "Trim leading and trailing whitespace” alle unnötigen Leerzeichen in den Spalten entfernen.
4 Records in einer Zeile zusammenfassen
Um die Zeilen pro “record” zusammenzufassen, verwenden wir “Original 1"
"Edit Cells"
"Join multi-valued cells…” mit der Trennsequzent -:::- und verfahren bei Spalte Original 2 ebenso.
Das Ergebnis ist in Abbildung 7 gezeigt.

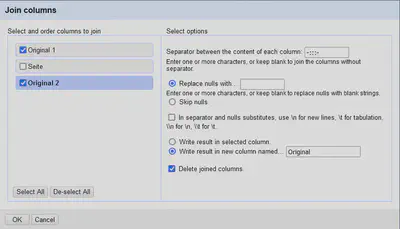
5 Spalten zusammenführen
Die Spalten Original 1 und 2 werden über “Original 1" "Edit column" "Join columns…” wieder in der Spalte Original zusammengeführt. Die Einstellungen sind in Abbildung 8 abgebildet.
Das Ergebnis ist in Abbildung 9 gezeigt.

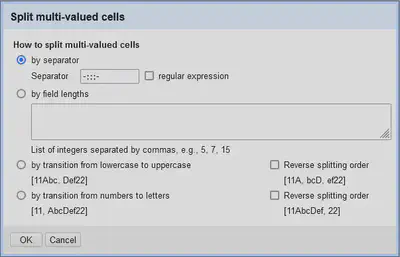
6 Zeilen auftrennen
Um die einzelnen Zeilen wieder aufzutrennen, verwenden wir “Original"
"Edit Cells"
"Split multi-valued cells…” mit der Trennsequenz -:::-, wie im Dialog in Abbildung 10 abgebildet.
Das Ergebnis ist in Abbildung 11 gezeigt.
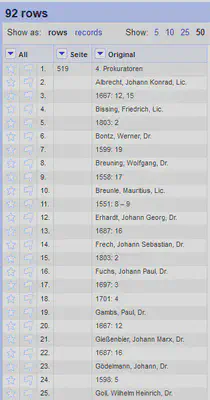
Anschließend können wir alle Zeilen mit Seitennummern entfernen und die Spalte Seite löschen. Dafür ein “Text Facet” auf der Spalte Seite erstellen und die entsprechenden Zeilen auswählen und löschen.
3. Informationen zu Prokuratoren zusammenführen
Wir haben in den vorangegangenen Schritten das zweispaltige Layout in ein einspaltiges Layout überführt und wollen nun für jeden Prokurator ein “record” erzeugen. Dafür trennen wir die Zeilen in einzelne Spalten für Name, (Wirkungs-)Jahre und Verweise auf. Anschließend transformieren wir die einzelnen Spalten, um zum Beispiel die Jahre und Verweise zusammenzufassen.
Informationen auftrennen
Spalte Name
Wir erzeugen von der Spalte Original aus eine neue Spalte Name mit einer “expression”.
Dafür suchen wir mit dem regulären Ausdruck [A-Z].+ nach Zeilen, die mit einem Großbuchstaben beginnen.
value.match(/([A-Z].+)/)[0]
Spalte Jahre
Wir erzeugen von der Spalte Original aus eine neue Spalte Jahre mit einer “expression”.
Dafür suchen wir mit dem regulären Ausdruck (\d{4}):.+ nach Zeilen, die mit vier Zahlen gefolgt von einem Doppelpunkt beginnen.
Davon extrahieren wir die vier Zahlen.
value.match(/(\d{4}):.+/)[0]
Spalte Verweise
Wir erzeugen von der Spalte Original aus eine neue Spalte Verweise mit einer “expression”.
Dafür suchen wir mit dem regulären Ausdruck \d{4}:(.+) nach Zeilen, die mit vier Zahlen gefolgt von einem Doppelpunkt beginnen.
Davon extrahieren wir alles nach dem Doppelpunkt.
value.match(/\d{4}:(.+)/)[0]
Spalten umformatieren
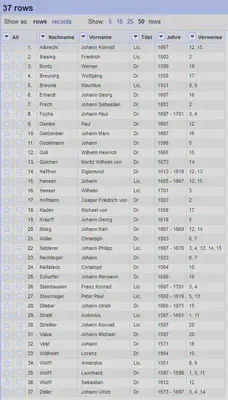
Die Spalte Original benötigen wir nicht mehr und können sie löschen. Wir verschieben anschließend die Spalte Name an den Anfang, da sie die “records” definiert.
Das Ergebnis ist in Abbildung 12 gezeigt. Anschließend formatieren wir die einzelnen Spalten.
Spalte Jahre
Die Jahre im Beispiel 1797, 1767, 1770, 1801 wollen wir als Zeitraum im Format 1767 - 1801 zusammenfassen.
Dafür führen wir die Zeilen der Spalte Jahre via “Jahre"
"Edit Cells"
"Join multi-valued cells…” mit der Trennsequenz ,\s+ zusammen.
Die Spalte Jahre transfomieren wir anschließend via “Jahre" "Edit cells" "Transform…”. Dafür bestimmen wir das Minimum und das Maximum in der Liste der Zahlen. Leider gibt es in GREL keine Funktion, die das auf einer Liste (technisch Array) für uns übernehmen kann. Daher gehen wir wie folgt vor:
- Wir erzeugen eine Liste
years, indem wir mitsplit()an der Sequenz,\s+trennen. - Die einzelnen Jahre
yearwandeln wir in einerforEachSchleife mittoNumber()in Zahlen um, da sie sonst “fehlerhaft” sortiert werden ("1, 10, 11, 2, 20, ..."). - Wir sortieren die Liste
yearsmitsort(). - Hat die Liste
yearsnur ein Jahr, dann wandeln wir es mittoString()in Text um. - Hat die Liste
yearsmehrere Elemente, nehmen wir das erste (Minimum) und das letzte Element (Maximum). Durch die Verbindung über-wird automatisch ein Text erzeugt.
with(
forEach(
value.split(/,\s+/),
year,
year.toNumber())
.sort(),
years,
if(
years.length() < 2,
years[0].toString(),
years[0] + " - " + years[-1]))
Spalte Verweise
Die Verweise führen wir ebenfalls via “Verweise"
"Edit Cells"
"Join multi-valued cells…” mit der Trennsequenz ,\s+ zusammen.
Die Spalte Verweise transfomieren wir anschließend via “Verweise" "Edit cells" "Transform…”. Bei den Verweisen haben wir mehrere Probleme:
- Teilweise werden sie als Bereiche
8-10angegeben, die wir in8, 9, 10überführen wollen. - Es werden zwei verschiedene Bindestriche verwendet, die optisch gleich aussehen.
- Wir können Duplikate bei den Verweisen haben.
- Die Reihenfolge kann durcheinander sein.
Die “expression” um diese Probleme zu behandeln, ist daher komplex. Hier eine Erklärung des Vorgehens:
- Wir trennen die Verweise mit dem regulären Ausdruck
,\s+in eine Liste (technisch Array). - Jeden der Verweise
vin der Liste trennen wir anschließend mit dem regulären Ausdruck–|\-(unterschiedliche Bindestriche) und nennen das Ergebnisv2. - Wenn der Verweis
v2mehrere Elemente hat (es also ein Bereich mit Bindestrich war), dann erzeugen wir mit forRange eine Zahlenliste über diesem Bereich, und verbinden die Zahlen mitjoin(",")zu einem Text. - Jetzt haben die Bereiche und die einzelnen Verweise das gleiche Format. Also verbinden wir sie ebenfalls mit
join(","). - Den verbundenen Text trennen wir anschließend wieder mit
,in eine Liste mit einzelnen Verweisen und wandeln die einzelnen VerweisevmittoNumber()in Zahlen um. - Da wir nun eine Liste mit Zahlen haben, können wir mit
uniques()die doppelten Verweise entfernen und sie mitsort()sortieren. - Die bereinigte Liste wandeln wir mit
join(", ")anschließend wieder in einen Text um.
forEach(
forEach(
value.trim().split(/,\s+/),
v,
with(
v.split(/–|\-/),
v2,
if(
v2.length() > 1,
forRange(v2[0].toNumber(), v2[1].toNumber() + 1, 1, i, i).join(","),
v2[0]))
)
.join(",")
.split(/,/),
v,
v.toNumber())
.uniques()
.sort()
.join(", ")
Spalte Name
Diese Spalte bearbeiten wir als letzte, da wir ansonsten die “record” Struktur verloren hätten. Die “record” Struktur haben wir in den vorherigen Schritten benötigt, um die Jahre und Verweise in einer Zeile zusammenzufassen.
Wir wollen die Spalte Name in Vorname, Nachname und Titel trennen.
Das erleichtert uns das Überführen in andere Formate zum Beispiel für den Abgleich mit der GND oder das Umwandeln in ein Deskriptorenformat.
Dafür trennen wir die Spalte Name via “Name"
"Edit Cells"
"Split into several columns…” in drei Spalten am Trennzeichen , auf und lassen sie auch gleich entfernen.
Die entsprechenden Einstellungen sind in Abbildung 13 gezeigt.
Die Daten sind nun sauber aufgetrennt und können zur weiteren Verarbeitung verwendet werden. Das Ergebnis ist in Abbildung 14 gezeigt.
4. Abgleich mit der Gemeinsamen Normdatei
Als Bonus gleichen wir die Prokuratoren mit der Gemeinsamen Normdatei (GND) ab. Der Vorgang wird in OpenRefine Reconciling genannt. Dafür verwenden wir den GND Reconciliation Service von lobid. Die Verwendung ist in einem lobid Blogeintrag ausführlich erklärt.
Bei uns hat sich das folgende Vorgehen bewährt.
Zuerst erzeugen wir via “Nachname" "Edit column" "Join columns…” eine neue Spalte Name, wo wir die Namensstruktur “Nachname, Vorname” der GND übernehmen. 1 Anschließend können wir via “Name" "Reconcile" "Start reconciling” den Vorgang starten.
Falls noch nicht geschehen, den “lobid gnd service” via “Add Standard Service…” mit der URL https://lobid.org/gnd/reconcile hinzufügen und auswählen.
Die entsprechenden Einstellungen für den Abgleichvorgang sind in Abbildung 15 abgebildet. Wir fügen den Titel als separate Spalte hinzu, da wir dadurch bessere Ergebnisse erzielen konnten. Leider können wir die (Wirkungs-)Jahre nicht berücksichtigen, da es keine kleiner/größer Operation für den “Reconciliation Service” gibt.
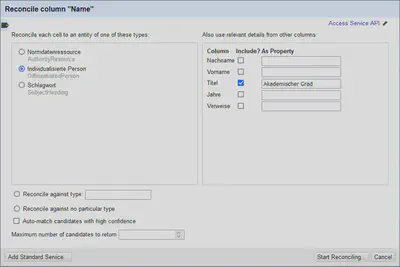
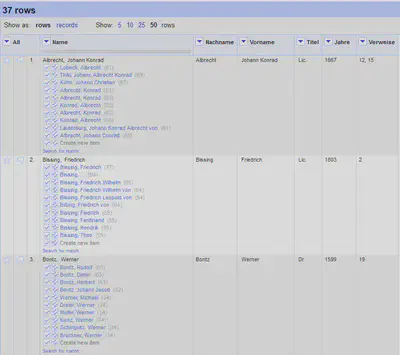
Das Ergebnis ist in Abbildung 16 gezeigt. Jetzt können mit einer Mischung aus Heuristik (zum Beispiel alle Treffer mit Übereinstimmung von mehr als 95 % automatisch übernehmen) und manueller Prüfung die einzelnen Personen verknüpft werden.
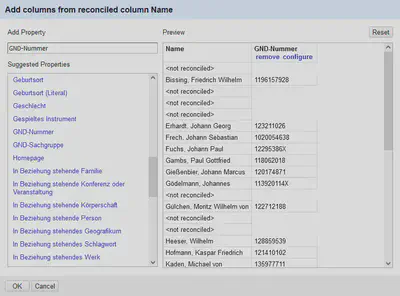
Anschließend wollen wir die GND-ID als zusätzliche Spalte in unserem Datensatz haben. Das funktioniert über “Name" "Edit columns" "Add columns from reconciled values…”, wo wir die GND-ID wie in dem in Abbildung 17 dargestellten Dialog auswählen können.
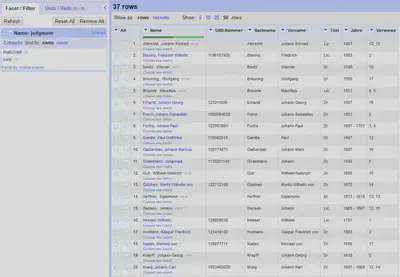
Wir konnten 18 der 37 Prokuratoren aus unserem Datensatz in der GND identifizieren und verknüpfen. Das Ergebnis ist in Abbildung 18 gezeigt.
5. Umwandlung in Deskriptorenformat
Aus den einzelnen Datenbestandteilen können wir nun einen Deskriptor für unser AFIS zusammensetzen.
Dafür gehen wir zu einer beliebigen Spalte, um von dort aus mit einer “expression” eine neue Spalte Deskriptor im Format Nachname, Vorname Titel; Prokurator am Reichskammergericht {Wirkungsjahre} | {Optionale GND-ID} zu erzeugen. 2
cells["Nachname"].value.trim()
+ ", " + cells["Vorname"].value.trim()
+ " " + cells["Titel"].value.trim()
+ "; Prokurator am Reichskammergericht " + cells["Jahre"].value.trim()
+ if(isNonBlank(cells["GND-Nummer"]),
" | " + cells["GND-Nummer"].value,
"")
Das Endergebnis ist in Abbildung 19 gezeigt.
Index Prokuratoren Akten RKG Band 57 - Wertheim als OpenRefine Arbeitsschritte .💾 Die einzelnen Arbeitsschritte im OpenRefine Format:
Fazit
Wir haben mit OpenRefine den Prokuratoren Index eines Findbuchs zu Akten des Reichskammergerichts aus einem zweispaltigen Layout in ein einspaltiges Layout überführt, den Datensatz aufbereitet und die einzelnen Prokuratoren mit der GND abgeglichen.
Die Operationen zum Aufräumen der Daten (Jahre und Verweise) waren diesmal komplex, lassen sich jedoch auf ähnliche Probleme übertragen.
Es bleibt die Erkenntnis, dass der Abgleich von Personen mit dem “Reconciliation Service” von lobid deutlich komfortabler wäre, wenn es möglich wäre eine zeitliche Einschränkung der Lebens- und Wirkungsdaten vorzunehmen. 3
Die Zuordnung der Daten erfolgt über den “Reconciliation Service”. Manche verwenden Verfahren, bei denen eine Übereinstimmung im Format relevant ist und zu besseren Ergebnissen führt. Andere verwenden Verfahren, bei denen die Reihenfolge der Suchbegriffe komplett ignoriert wird. ↩︎
Uns ist gegen Ende aufgefallen, dass wir noch überflüssige Leerzeichen in den einzelnen Spalten haben. Anstatt sie im Deskriptor mit
trim()zu entfernen, wäre es sinnvoller gewesen sie vorher mit “All" "Trim leading and trailing whitespace” zu entfernen. ↩︎Update April 2022: Durch ein Update in dem lobid GND API für OpenRefine kann nun eine zeitliche Einschränkung beim Reconciliation vorgenommen werden. Details dazu finden sich unter Using range query parameter via OpenRefine Reconciliation auf GitHub und unter Erweiterter GND Abgleich mit lobid auf unserem Blog. ↩︎
Benjamin Rosemann
Data Scientist
Ich evaluiere KI- und Software-Lösungen und integriere sie in den Archivalltag.