Analyse tabellarischer Layoutstrukturen mit Transkribus
 Photo by jan mesaros on Pixabay.
Photo by jan mesaros on Pixabay.Eine gute Layouterkennung ist die Voraussetzung für eine gute OCR- oder HTR-Erfassung von Dokumenten. Anhand von Stammrollen aus dem LABW testen wir, welche Möglichkeiten Transkribus bei der Layouterkennung komplexer Tabellenstrukturen bietet.
Unser Ausgangsmaterial: Stammrollen mit Tabellen-Layout
Die militärischen Bestände des LABW aus dem Zeitraum zwischen 1871 bis ca. 1920 beinhalten u.a. umfangreiche militärische Personalunterlagen. Dazu gehören die sogenannten Kriegs- und Friedensstammrollen von verschiedenen Regimentern. Diese listen alle Angehörigen einer Einheit mit Daten zur Person, den Angehörigen, mitgemachten Gefechten, Auszeichnungen etc. auf. Die Stammrollen sind für viele unterschiedliche Forschungsfragen interessant und insbesondere auch für Genealogen eine gerne genutzte historische Quelle.
Die Stammrollen sind bereits vollständig digitalisiert und über das Online Findmittelsystem (OLF) des LABW einsehbar.1 Durch eine zusätzliche Volltexterfassung der Namen und Geburtsdaten aus den Stammrollen könnte man schnell und bequem nach einer bestimmten Person suchen. Das wäre ein echter Mehrwert für genealogische Forschungen! Wir testen, wie wir dies mit Transkribus umsetzen können.
Hier zuerst ein Blick auf das Layout unserer Stammrollen:
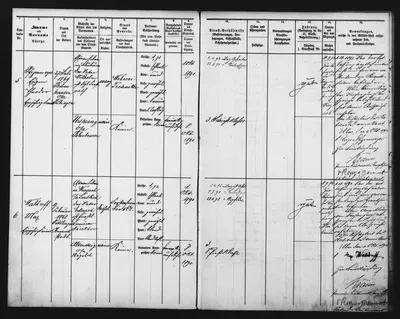
Layouterkennung als Basis für die Transkription
Die Layoutanalyse ist in Transkribus der erste Schritt, bevor man ein Dokument manuell oder automatisiert transkribieren kann. Bei der Layoutanalyse wird ein Dokument in Textregionen, Zeilen und Basislinien unterteilt. Die Texterkennung arbeitet auf der Basis dieser Segmentierung. Ausführliche Informationen, wie man die automatische Layoutanalyse durchführen kann, gibt es auf der Transkribus-Website.2
Wir testen, wie gut die automatische Layoutanalyse bei unseren Stammrollen funktioniert.
Ergebnisse der automatischen Layoutanalyse
Schon ein kurzer Blick auf eine Seite aus unseren Stammrollen zeigt, dass wir es mit einem komplexen Layout zu tun haben: Unsere Tabelle besitzt 15 Spalten mit Spaltenüberschriften. Auf einer (Doppel-)Seite gibt es in der Regel zwei Einträge, sprich Zeilen. Die Zellen innerhalb einer Zeile sind teilweise noch einmal in zwei kleinere Zellen unterteilt. Was wir als Menschen sofort verstehen, stellt an Transkribus hohe Anforderungen bei der richtigen Erkennung von Textabschnitten und Zeilen und der Festlegung der Lesereihenfolge der einzelnen Elemente. Wir haben Transkribus eine harte Nuss zu knacken gegeben!
Die Ergebnisse der automatischen Layoutanalyse sind dementsprechend fehlerhaft. Der Großteil des Textes wurde als Textzeilen erkannt. Vor allem in den Spaltenüberschriften, vereinzelt auch in den Tabelleneinträgen, gibt es aber auch Textzeilen, die nicht als solche erkannt wurden.
Bei der Erkennung der Textregionen scheint Transkribus sich insgesamt an den Tabellenspalten zu orientieren. Dies hat jedoch nicht zufriedenstellend funktioniert. Während einerseits mehrere Tabellenspalten in einer Textregion zusammengefasst wurden, sind andere Spalten in mehrere Regionen aufgeteilt worden, die sich teilweise auch überlappen.
Auch, wenn das Layout der Tabelle auf jeder Seite dasselbe ist, werden bei jeder Seite unterschiedliche Textregionen erkannt, da die Textverteilung sich auf den Seiten unterscheidet. Das Ergebnis der automatischen Layoutanalyse ist daher bei gleichen Voreinstellung auf jeder Seite etwas anders.
Die fehlerhaften Textregionen stellen deshalb ein Problem dar, weil dadurch auch die Lesereihenfolge der Zeilen durcheinandergerät.

Manuelle Bearbeitungsmöglichkeiten
Um zu einem brauchbaren Ergebnis zu kommen, sind manuelle Nacharbeiten erforderlich. Transkribus stellt uns dafür umfangreiche Möglichkeiten zur Verfügung. Eine detaillierte Anleitung findet sich ebenfalls auf der Transkribus-Website.3 Zuerst müssen die Textregionen korrigiert werden. Sinnvoll ist es hier, jeweils eine Tabellenzelle als eine Textregion zu kennzeichnen.4 Nachdem die Lesereihenfolge der Textregionen berichtigt wurde, werden auch die Basislinien innerhalb der Textregionen manuell korrigiert, wo dies nötig ist. Abschließend wird die Lesereihenfolge der Zeilen angegeben.
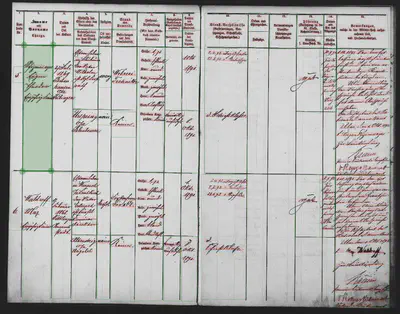
Tipps für manuelle Layoutkorrekturen
- Um fehlerhafte Textzeilen zu korrigieren, müssen Sie die Basislinien korrigieren, an denen sich die Texterkennung orientiert. Die Zeilen werden dann automatisch ebenfalls angepasst.
- Wenn Sie Text aus einer Textregion auf zwei unterschiedliche Textregionen aufteilen möchten, nutzen Sie das Werkzeug zum Zerschneiden von Elementen (gekennzeichnet durch das Scherensymbol). Nur so werden die Zeilen korrekt zu zwei Regionen zugeordnet.
- Achten Sie darauf, dass sich Textregionen nicht überlappen.
Fazit
Die automatische Layoutanalyse von Transkribus, die bei einfachen Layouts durchaus überzeugend funktionieren mag, kann ein komplexes Tabellenlayout wie das unserer Stammrollen nicht mit ausreichender Qualität verarbeiten. Transkribus bietet uns umfangreiche Möglichkeiten, die Layouterkennung manuell nachzubearbeiten. So haben wir am Ende unseres Tests die Seite aus der Stammrolle zufriedenstellend segmentiert. Die Nacharbeiten nehmen jedoch viel Zeit in Anspruch, sodass dieses Vorgehen nicht geeignet ist, um unseren gesamten Bestand an Kriegs- und Friedensstammrollen im LABW zu bearbeiten.
Um einen effizienteren Weg zu finden, unser Tabellenlayout zu analysieren, werden wir als nächstes das Tool P2PaLA testen, welches in Transkribus integriert und ab Version 1.15.1 für alle Transkribus User freigeschaltet ist. Mit P2PaLA lässt sich ein spezifisches Strukturmodell für die Layouterkennung einer Dokumentensammlung trainieren. Auf diese Weise möchten wir einen höheren Automatisierungsgrad bei der Erkennung unseres Stammrollen-Tabellenlayouts erreichen. Wir werden in einem Folgebeitrag davon berichten.
Die Bestände des Hauptstaatsarchivs Stuttgart HStA M 430/1 - M631 in OLF. ↩︎
Anleitung zur Layoutanalyse mit Transkribus im Transkribus-Ressourcenzentreum der READ COOP. ↩︎
Anleitung „Wie man Dokumente mit Transkribus transkribiert“ im Transkribus-Ressourcenzentreum der READ COOP. ↩︎
Grundsätzlich kennt das von Transkribus verwendete PAGE XML Format auch Tabellen. Jedoch werden rekursive Strukturen (Tabelle -> Zelle -> Text) unserer Erfahrung nach nicht von allen Werkzeugen zuverlässig unterstützt. ↩︎
Elisabeth Klindworth
Archivarin
Ich arbeite daran, maschinelles Lernen in Form automatisierter Erkennung und Annotation digitaler Texte und Bilder in den Archivalltag zu integrieren, um Archivgut noch besser nutzbar zu machen.